Tulemuse statistiline olulisus (p-väärtus) on selle „tõe” (“valimi representatiivsuse” tähenduses) usaldusväärsuse hinnanguline mõõt. Tehnilisemalt öeldes on p-väärtus mõõt, mis varieerub vastavalt tulemuse usaldusväärsusele kahanevas suurusjärgus. Kõrgem p-väärtus vastab valimis leitud muutujate vahelise seose madalamale usaldustasemele. Täpsemalt, p-väärtus tähistab vea tõenäosust, mis on seotud vaadeldava tulemuse üldistamisega kogu populatsioonile. Näiteks p-väärtus 0,05 (s.o 1/20) näitab, et 5% tõenäosusega on valimis leitud muutujate vaheline seos vaid valimi juhuslik tunnus. Teisisõnu, kui antud seost populatsioonis ei eksisteeri ja teete sarnaseid katseid mitu korda, siis umbes iga kahekümne katse korduse korral eeldate muutujate vahel sama või tugevamat seost.
Paljudes uuringutes peetakse p-väärtust 0,05 veataseme "vastuvõetavaks marginaaliks".
Ei saa kuidagi vältida meelevaldsust otsustamisel, millist olulisuse taset tuleks tõeliselt „oluliseks” pidada. Teatud olulisuse taseme valik, millest kõrgemad tulemused lükatakse tagasi kui valed, on üsna meelevaldne. Praktikas sõltub lõplik otsus tavaliselt sellest, kas tulemus ennustati a priori (st enne katse läbiviimist) või avastati tagantjärele paljude erinevate andmete analüüside ja võrdluste tulemusena, samuti õppesuuna traditsiooni. Tavaliselt on paljudes valdkondades tulemus p 0,05 statistilise olulisuse vastuvõetav piir, kuid tuleb meeles pidada, et see tase sisaldab siiski üsna suurt veamäära (5%). P 0,01 tasemel olulisi tulemusi peetakse üldiselt statistiliselt olulisteks ja p 0,005 või p 0,001 tasemega tulemusi peetakse üldiselt väga olulisteks. Siiski tuleb mõista, et see olulisuse tasemete klassifikatsioon on üsna meelevaldne ja on lihtsalt mitteametlik kokkulepe, mis on vastu võetud konkreetses uurimisvaldkonnas saadud praktiliste kogemuste põhjal.
Nagu juba mainitud, esindavad seose suurus ja usaldusväärsus muutujatevaheliste seoste kaht erinevat tunnust. Samas ei saa öelda, et nad oleksid täiesti iseseisvad. Üldiselt võib öelda, et mida suurem on normaalsuuruses valimi muutujate vahelise seose (seos) suurus, seda usaldusväärsem see on.
Kui eeldada, et üldkogumis vastavate muutujate vahel seos puudub, siis kõige tõenäolisemalt eeldatakse, et uuritavas valimis puudub ka seos nende muutujate vahel. Seega, mida tugevam seos valimist leitakse, seda väiksem on tõenäosus, et seost ei eksisteeri populatsioonis, millest see on võetud.
Valimi suurus mõjutab suhte olulisust. Kui vaatlusi on vähe, on nende muutujate jaoks vastavalt vähe võimalikke väärtuskombinatsioone ja seega on tugevat seost näitava väärtuskombinatsiooni kogemata avastamise tõenäosus suhteliselt suur.
Kuidas arvutatakse statistilise olulisuse taset. Oletame, et olete juba arvutanud kahe muutuja vahelise sõltuvuse (nagu eespool selgitatud). Järgmine küsimus, mis teie ees seisab, on: "Kui oluline see suhe on?" Näiteks kas 40% seletatud dispersioon kahe muutuja vahel on piisav, et pidada seost oluliseks? Vastus: "sõltuvalt asjaoludest." Nimelt oleneb olulisus peamiselt valimi suurusest. Nagu juba selgitatud, on väga suurtes valimites isegi väga nõrgad seosed muutujate vahel olulised, samas kui väikestes valimites ei ole isegi väga tugevad seosed usaldusväärsed. Seega on statistilise olulisuse taseme määramiseks vaja funktsiooni, mis esindab iga valimi suuruse muutujate vahelise seose "suuruse" ja "olulisuse" vahelist seost. See funktsioon annab teile täpselt teada, „kui tõenäoline on antud väärtusega (või suurema) seose saavutamine antud suurusega valimi puhul, eeldades, et populatsioonis sellist seost pole”. Teisisõnu annaks see funktsioon olulisuse taseme (p-väärtuse) ja seega ka tõenäosuse, et lükatakse ekslikult ümber eeldus, et antud seost populatsioonis ei eksisteeri. Seda "alternatiivset" hüpoteesi (et populatsioonis pole seost) nimetatakse tavaliselt nullhüpoteesiks. Ideaalne oleks, kui vea tõenäosust arvutav funktsioon oleks lineaarne ja sellel oleks ainult erinevate valimi suuruste puhul erinevad kalded. Kahjuks on see funktsioon palju keerulisem ega ole alati täpselt sama. Kuid enamikul juhtudel on selle vorm teada ja seda saab kasutada olulisuse taseme määramiseks antud suurusega proovide uuringutes. Enamik neist funktsioonidest on seotud väga olulise jaotuste klassiga, mida nimetatakse normaalseks.
Regressioonimudeli koostamisel tekib küsimus regressioonivõrrandis (1) sisalduvate tegurite olulisuse määramisest. Faktori olulisuse määramine tähendab küsimuse selgitamist teguri mõju tugevuse kohta reageerimisfunktsioonile. Kui teguri olulisuse kontrollimise ülesande lahendamise käigus selgub, et tegur on väheoluline, siis võib selle võrrandist välja jätta. Sel juhul leitakse, et tegur ei mõjuta oluliselt reageerimisfunktsiooni. Kui teguri olulisus leiab kinnitust, siis jäetakse see regressioonimudelisse. Arvatakse, et sel juhul on sellel teguril mõju reaktsioonifunktsioonile, mida ei saa tähelepanuta jätta. Faktorite olulisuse küsimuse lahendamine on samaväärne hüpoteesi kontrollimisega, et nende tegurite regressioonikoefitsiendid on võrdsed nulliga. Seega on nullhüpotees järgmine: , kus on mõõtmevektori (l*1) alamvektor. Kirjutame regressioonivõrrandi ümber maatriksi kujul:
Y = Xb+e,(2)
Y– vektor suurusega n;
X- suurusmaatriks (p*n);
b on vektor suurusega p.
Võrrandi (2) saab ümber kirjutada järgmiselt:
 ,
,
Kus X l ja X p - l - vastavalt (n,l) ja (n,p-l) suuruse maatriksid. Siis on hüpotees H 0 samaväärne eeldusega, et
 .
.
Määrame funktsiooni miinimumi  . Kuna vastavate hüpoteeside H 0 ja H 1 = 1 - H 0 all hinnatakse teatud lineaarse mudeli kõiki parameetreid, on hüpoteesi H 0 miinimum võrdne
. Kuna vastavate hüpoteeside H 0 ja H 1 = 1 - H 0 all hinnatakse teatud lineaarse mudeli kõiki parameetreid, on hüpoteesi H 0 miinimum võrdne
 ,
,
samas kui H 1 puhul on see võrdne
 .
.
Nullhüpoteesi kontrollimiseks arvutame statistika  , millel on (l,n-p) vabadusastmega Fisheri jaotus ja H 0 kriitiline piirkond moodustatakse 100*a protsendiga F suurimatest väärtustest. Kui F
, millel on (l,n-p) vabadusastmega Fisheri jaotus ja H 0 kriitiline piirkond moodustatakse 100*a protsendiga F suurimatest väärtustest. Kui F
Faktorite olulisust saab kontrollida muu meetodi abil, üksteisest sõltumatult. See meetod põhineb regressioonivõrrandi kordajate usaldusvahemike uurimisel. Määrame koefitsientide dispersioonid,  Väärtused on maatriksi diagonaalsed elemendid
Väärtused on maatriksi diagonaalsed elemendid  . Pärast koefitsientide dispersioonide hinnangute määramist saab konstrueerida usaldusvahemikud regressioonivõrrandi koefitsientide hinnangute jaoks. Iga hinnangu usaldusvahemik on
. Pärast koefitsientide dispersioonide hinnangute määramist saab konstrueerida usaldusvahemikud regressioonivõrrandi koefitsientide hinnangute jaoks. Iga hinnangu usaldusvahemik on  , kus on elemendi määramise vabadusastmete arvu ja valitud olulisuse taseme Studenti kriteeriumi tabeliväärtus. Tegur arvuga i on oluline, kui selle teguri koefitsiendi absoluutväärtus on suurem kui usaldusvahemiku koostamisel arvutatud hälve. Teisisõnu, arvuga i tegur on oluline, kui 0 ei kuulu selle koefitsiendi hinnangu jaoks konstrueeritud usaldusvahemikku. Praktikas on nii, et mida kitsam on antud olulisuse tasemel usaldusvahemik, seda kindlamad saame teguri olulisuses olla. Faktori olulisuse kontrollimiseks Studenti testi abil saate kasutada valemit
, kus on elemendi määramise vabadusastmete arvu ja valitud olulisuse taseme Studenti kriteeriumi tabeliväärtus. Tegur arvuga i on oluline, kui selle teguri koefitsiendi absoluutväärtus on suurem kui usaldusvahemiku koostamisel arvutatud hälve. Teisisõnu, arvuga i tegur on oluline, kui 0 ei kuulu selle koefitsiendi hinnangu jaoks konstrueeritud usaldusvahemikku. Praktikas on nii, et mida kitsam on antud olulisuse tasemel usaldusvahemik, seda kindlamad saame teguri olulisuses olla. Faktori olulisuse kontrollimiseks Studenti testi abil saate kasutada valemit  . Arvutatud t-testi väärtust võrreldakse tabeli väärtusega etteantud olulisuse tasemel ja vastava arvu vabadusastmete juures. Seda tegurite olulisuse kontrollimise meetodit saab kasutada ainult siis, kui tegurid on sõltumatud. Kui on põhjust pidada mitmeid üksteisest sõltuvaid tegureid, saab seda meetodit kasutada ainult tegurite järjestamiseks vastavalt nende mõju astmele reageerimisfunktsioonile. Olulisuse testi selles olukorras tuleb täiendada Fisheri kriteeriumil põhineva meetodiga.
. Arvutatud t-testi väärtust võrreldakse tabeli väärtusega etteantud olulisuse tasemel ja vastava arvu vabadusastmete juures. Seda tegurite olulisuse kontrollimise meetodit saab kasutada ainult siis, kui tegurid on sõltumatud. Kui on põhjust pidada mitmeid üksteisest sõltuvaid tegureid, saab seda meetodit kasutada ainult tegurite järjestamiseks vastavalt nende mõju astmele reageerimisfunktsioonile. Olulisuse testi selles olukorras tuleb täiendada Fisheri kriteeriumil põhineva meetodiga.
Seega käsitletakse tegurite olulisuse kontrollimise ja mudeli dimensiooni vähendamise probleemi tegurite ebaolulise mõju korral reageerimisfunktsioonile. Edasi oleks siinkohal loogiline käsitleda mudelisse lisategurite lisamist, mida teadlase sõnul katse käigus ei arvestatud, kuid nende mõju reageerimisfunktsioonile on märkimisväärne. Oletame, et pärast regressioonimudeli valimist
 ,
,  ,
,
tekkis ülesanne lisada mudelisse täiendavad tegurid x j nii, et nende tegurite kasutuselevõtuga mudel saaks järgmise kuju:
 , (3)
, (3)
kus X on maatriks suurusega n*p auastmega p, Z on maatriks suurusega n*g auastmega g ja maatriksi Z veerud on maatriksi X veergudest lineaarselt sõltumatud, st. maatriksil W suurusega n*(p+g) on auaste (p+g). Avaldis (3) kasutab tähistust (X,Z)=W,  . Äsja kasutusele võetud mudelikoefitsientide hinnangute määramiseks on kaks võimalust. Esiteks leiate hinnangu ja selle dispersioonimaatriksi otse seostest
. Äsja kasutusele võetud mudelikoefitsientide hinnangute määramiseks on kaks võimalust. Esiteks leiate hinnangu ja selle dispersioonimaatriksi otse seostest
Statistika on juba ammu muutunud elu lahutamatuks osaks. Inimesed kohtavad seda kõikjal. Statistika põhjal tehakse järeldused selle kohta, kus ja millised haigused on levinud, mille järele on konkreetses piirkonnas või teatud elanikkonnarühmas suurem nõudlus. Sellel põhinevad isegi valitsuskandidaatide poliitilised programmid. Neid kasutavad kaupade ostmisel ka jaeketid ning nendest andmetest juhinduvad ka tootjad oma pakkumistes.
Statistika mängib ühiskonnaelus olulist rolli ja mõjutab iga üksikut liiget ka pisiasjades. Näiteks kui enamik inimesi eelistab teatud linnas või piirkonnas riietuses tumedaid värve, siis lillelise trükiga erkkollase vihmamantli leidmine kohalikest jaemüügipunktidest on äärmiselt keeruline. Kuid millised kogused moodustavad need andmed, millel on selline mõju? Näiteks, mida kujutab endast „statistiline olulisus”? Mida see definitsioon täpselt tähendab?
Mis see on?
Statistika kui teadus koosneb erinevate suuruste ja mõistete kombinatsioonist. Üks neist on mõiste "statistiline tähtsus". See on muutujate väärtuse nimi, mille puhul teiste näitajate ilmnemise tõenäosus on tühine.
Näiteks 9 inimest kümnest paneb hommikusel jalutuskäigul pärast vihmast ööd sügismetsa seeni korjama kummikingad jalga. Tõenäosus, et ühel hetkel kannavad 8 neist lõuendist mokassiine, on tühine. Seega on selles konkreetses näites number 9 väärtus, mida nimetatakse statistiliseks olulisuseks.
Vastavalt sellele, kui arendada välja järgmine praktiline näide, ostavad kingapoed suvehooaja lõpupoole kummikuid suuremas koguses kui muul aastaajal. Seega mõjutab statistilise väärtuse suurus igapäevaelu.
Muidugi, keerulistes arvutustes, näiteks viiruste leviku ennustamisel, võetakse arvesse suurt hulka muutujaid. Kuid statistiliste andmete olulise näitaja määramise olemus on sarnane, sõltumata arvutuste keerukusest ja mittekonstantsete väärtuste arvust.
Kuidas seda arvutatakse?
Neid kasutatakse võrrandi „statistilise olulisuse“ indikaatori väärtuse arvutamisel. See tähendab, et võib väita, et antud juhul otsustab kõik matemaatika. Lihtsaim arvutusvõimalus on matemaatiliste toimingute ahel, mis hõlmab järgmisi parameetreid:
- kahte tüüpi uuringutest või objektiivsete andmete uurimisest saadud tulemusi, näiteks summad, mille eest oste tehakse, tähistatud a ja b;
- mõlema rühma näitaja - n;
- koondvalimi osa väärtus - p;
- "standardvea" mõiste - SE.
Järgmise sammuna määratakse üldine testinäitaja - t, selle väärtust võrreldakse numbriga 1,96. 1,96 on keskmine väärtus, mis esindab 95% vahemikku vastavalt Studenti t-jaotuse funktsioonile.

Sageli tekib küsimus, mis vahe on n ja p väärtustel. Selle nüansi saab näite abil lihtsalt selgeks teha. Oletame, et arvutame meeste ja naiste jaoks tootele või kaubamärgile lojaalsuse statistilist olulisust.
Sel juhul järgneb tähtede tähistele järgmine:
- n - vastajate arv;
- p - tootega rahulolevate inimeste arv.
Sel juhul küsitletud naiste arvuks märgitakse n1. Vastavalt on n2 meest. P-sümboli numbritel “1” ja “2” on sama tähendus.
Testindikaatori võrdlus Studenti arvutustabelite keskmiste väärtustega muutub nn statistiliseks olulisuseks.
Mida tähendab kontrollimine?
Iga matemaatilise arvutuse tulemusi saab alati kontrollida, lastele õpetatakse seda algkoolis. Loogiline on eeldada, et kuna statistilised näitajad määratakse arvutusahela abil, siis neid kontrollitakse.
Statistilise olulisuse testimine ei puuduta aga ainult matemaatikat. Statistika käsitleb suurt hulka muutujaid ja erinevaid tõenäosusi, mis pole alati arvutatavad. See tähendab, et kui pöördume tagasi artikli alguses toodud kummikingade näite juurde, siis võib statistiliste andmete loogilist ülesehitust, millele kaupluste kaupade ostjad loodavad, segada kuiv ja kuum ilm, mis ei ole tüüpiline. sügis. Selle nähtuse tulemusena väheneb kummikuid ostvate inimeste arv ning jaemüügipunktid kannavad kahju. Matemaatiline valem ei suuda mõistagi ilmaanomaaliat ennustada. Seda hetke nimetatakse "veaks".

Arvutatud olulisuse taseme kontrollimisel võetakse arvesse just selliste vigade tõenäosust. See võtab arvesse nii arvutatud näitajaid kui ka aktsepteeritud olulisuse tasemeid, aga ka väärtusi, mida tavaliselt nimetatakse hüpoteesideks.
Mis on olulisuse tase?
Mõiste "tase" sisaldub statistilise olulisuse peamistes kriteeriumides. Seda kasutatakse rakendus- ja praktilises statistikas. See on teatud tüüpi väärtus, mis võtab arvesse võimalike kõrvalekallete või vigade tõenäosust.
Tase põhineb valmisproovide erinevuste tuvastamisel ja võimaldab tuvastada nende olulisust või vastupidi juhuslikkust. Sellel kontseptsioonil pole mitte ainult digitaalset tähendust, vaid ka nende ainulaadset dekodeerimist. Nad selgitavad, kuidas väärtust tuleb mõista, ja tase ise määratakse tulemuse võrdlemisel keskmise indeksiga, see näitab erinevuste usaldusväärsust.

Seega võime taseme mõistet ette kujutada lihtsalt – see on vastuvõetava, tõenäolise vea või vea näitaja saadud statistiliste andmete põhjal tehtud järeldustes.
Milliseid olulisuse tasemeid kasutatakse?
Vea tõenäosuskoefitsientide statistiline olulisus praktikas põhineb kolmel põhitasandil.
Esimeseks tasemeks loetakse läve, mille juures väärtus on 5%. See tähendab, et vea tõenäosus ei ületa 5% olulisuse taset. See tähendab, et kindlus statistiliste uuringute andmete põhjal tehtud laitmatuse ja vigadeta järelduste suhtes on 95%.
Teine tase on 1% künnis. Seega tähendab see arv, et statistiliste arvutuste käigus saadud andmetest saab juhinduda 99% kindlusega.
Kolmas tase on 0,1%. Selle väärtuse korral on vea tõenäosus võrdne protsendi murdosaga, see tähendab, et vead on praktiliselt välistatud.
Mis on hüpotees statistikas?
Vead kui mõiste jagunevad kahte suunda, mis puudutavad nullhüpoteesi aktsepteerimist või tagasilükkamist. Hüpotees on mõiste, mille taga peitub definitsiooni kohaselt hulk muid andmeid või väiteid. See tähendab statistilise arvestuse ainega seotud millegi tõenäosusliku jaotuse kirjeldust.

Lihtsates arvutustes on kaks hüpoteesi – null ja alternatiiv. Nende erinevus seisneb selles, et nullhüpotees põhineb ideel, et statistilise olulisuse määramisel osalevate valimite vahel pole põhimõttelisi erinevusi ning alternatiivne hüpotees on täiesti vastupidine. See tähendab, et alternatiivne hüpotees põhineb valimiandmete olulise erinevuse olemasolul.
Millised on vead?
Vead kui mõiste statistikas sõltuvad otseselt ühe või teise hüpoteesi tõeseks tunnistamisest. Neid saab jagada kahte suunda või tüüpi:
- esimene tüüp on tingitud nullhüpoteesi aktsepteerimisest, mis osutub valeks;
- teine on põhjustatud alternatiivi järgimisest.

Esimest tüüpi vigu nimetatakse valepositiivseks ja see esineb üsna sageli kõigis valdkondades, kus kasutatakse statistilisi andmeid. Sellest lähtuvalt nimetatakse teist tüüpi viga valenegatiivseks.
Milleks kasutatakse statistikas regressiooni?
Regressiooni statistiline olulisus seisneb selles, et selle abil saab määrata, kui hästi vastab andmete põhjal arvutatud erinevate sõltuvuste mudel tegelikkusele; võimaldab tuvastada arvestatavate tegurite piisavust või puudumist ja teha järeldusi.
Regressiooniväärtus määratakse tulemuste võrdlemisel Fisheri tabelites loetletud andmetega. Või dispersioonanalüüsi kasutades. Regressiooninäitajad on olulised keeruliste statistiliste uuringute ja arvutuste jaoks, mis hõlmavad suurt hulka muutujaid, juhuslikke andmeid ja tõenäolisi muutusi.
Mõju olulisus on sisuliselt kompleksne (terviklik) hindamine. Mõju olulisuse kindlaksmääramine toimub mitmes etapis.
Etapp 1. Looduskeskkonna üksikutele komponentidele avaldatava mõju olulisuse määramiseks on vaja kasutada mõjukriteeriumidega tabeleid (tabelid 5-1, 5-2 ja 5-3). Mõju olulisuse skoor määratakse valemiga 1.
Q i = K i t x K ma olen x K i j
1 Lisandite süsteemi kasutati sotsiaal-majanduslikus metoodikas nullväärtuste olemasolu tõttu, mis muudavad võrrandi põhjaliku mõjuhinnangu käigus korrutamise ajal kehtetuks.
looduskeskkond
K i
integr - komplekshinnangu skoor vaadeldava mõju kohta;
Qi t- ajutise mõju skoor i-th looduskeskkonna komponent;
Qi s- ruumilise mõju skoor kohta i-th looduskeskkonna komponent;
Qi j- mõju intensiivsuse skoor kohta i-th looduskeskkonna komponent.
Olulisuse kategooriad on looduskeskkonna eri komponentide lõikes järjepidevad ja võivad olla juba võrreldavad, et määrata kindlaks looduskeskkonna komponent, millel on suurim mõju.
KMH läbiviimiseks on vastu võetud kolm mõju olulisuse kategooriat - väike, mõõdukas ja oluline, nagu on näidatud tekstikastis 5.
Tekstiraam 5
| Väikese tähtsusega mõju ilmneb siis, kui mõju on kogetud, kuid mõju ulatus on piisavalt väike (koos leevendusega või ilma) ja jääb vastuvõetavate normide piiresse või kui retseptorid on madala tundlikkusega/väärtusega. |
| Mõõduka tähtsusega mõju võib olla laiaulatuslik, alates künnisest, millest allpool on mõju madal, kuni tasemeni, mis on lähedal seadusest tulenevale piirile. Võimaluse korral tuleks tõendada mõõduka tähtsusega mõju vähenemist. |
| Suure tähtsusega mõjud ilmnevad vastuvõetavate piiride ületamisel või kui täheldatakse suure ulatusega mõjusid, eriti väärtuslikele/tundlikele ressurssidele. |
· mõjud muldadele ja aluspinnasele;
· mõjud pinna- ja merevetele;
· mõju põhjaveele;
· mõju põhjasetetele;
· mõju õhukvaliteedile;
· mõju mere ja maismaa bioloogilistele ressurssidele;
· mõjud maastikele;
· füüsilised mõjutegurid (müra mõju, vibratsioon jne).
Kui looduskeskkonna konkreetsele komponendile (atmosfääriõhk, elusloodus jne) määratud mõju olulisus on ainuke, siis kasutatakse seda otseselt sellest tuleneva mõju olulisuse hindamiseks.
Praktikas võib looduskeskkonna ühele komponendile avaldada mitmest allikast erinevaid mõjusid, mistõttu mõju olulisuse määramiseks kasutatakse saadud olulisuse hinnangut konkreetse looduskeskkonna komponendi kohta. Sõltuvalt saadud hinnetest ja olulisuse kriteeriumidest saab määrata saadud mõju olulisuse hinnangu. Näide tekkiva mõju olulisuse määramisest on toodud tabelis 5-5.
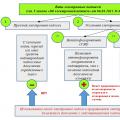
7. Keskkonnaaudit – keskkonnajuhtimise majanduslik tööriist
Keskkonnaaudit on keskkonnajuhtimise majanduslik tööriist.
Keskkonnaregulatsiooni majanduslik mehhanism on keerukas mitmetasandiline suhete süsteem äriüksuste omavahelistes ja kõrgemate võimuorganitega. Nende suhete ühendavaks hoovaks peaks olema keskkonnaaudit (EA) – tööriist, mis hõlmab keskkonnakaitse organisatsioonilisi ja majanduslikke tegureid. See võimaldab teil valida keskkonnakaitsestruktuuride jaoks parima võimaluse, korraldada teabe- ja analüütilist kontrolli keskkonnakaitseseadmete seisukorra ja tööastme üle ning anda kavandatavate tehniliste ja tehnoloogiliste täiustuste majandusliku hinnangu.
Lähtudes eesmärkidest, programmi väljatöötamise iseärasustest ja elluviimise metoodikast pakume välja järgmise definitsiooni: EA on sõltumatu uuring mis tahes omandivormiga tööstusettevõtte majandustegevuse kõigi aspektide kohta, et määrata otsese või kaudse mõju suurus. keskkonnaseisundi kohta. Selle eesmärk on viia keskkonnaalased tegevused vastavusse õigusaktide ja määruste nõuetega, optimeerida loodusvarade kasutamist, vähendada ja tõhustada energiatarbimist, vähendada jäätmeid, vältida avariiheiteid, heitmeid ja inimtegevusest tingitud katastroofe.
Kuna me räägime ettevõtte majandustegevuse kõigi aspektide uurimisest, peab EA ühendama ja laiendama juba olemasolevate audititüüpide programme ja meetodeid - tootmist, finantstegevust, vastavusauditeid.
Keskkonnaaudiitori aruanne sisaldab järgmist teavet:
o järeldused keskkonna- ja tootmistegevuse õigusaktidele ja määrustele vastavuse kohta;
o järeldus finantsmajandusliku aruandluse, arvestuse, jooksvate keskkonnamaksete õigeaegsuse ja suuruse, keskkonnakaitseks eraldatud kapitalivahendite kasutamise sihipärasuse kohta;
o auditeeritava ettevõtte mõju hindamine keskkonnaseisundile, tootmispersonali tervisele, piirkonna ökoloogiale, andmed saasteainete heitkoguste (heitmete) olemasolu ja suuruse kohta, mille tootmine on piiratud või keelatud riigi rahvusvaheliste kohustustega;
o toodete tootmise kasvutempo ning saasteainete heitkoguste ja heidete, energia- ja materiaalsete ressursside kulu analüüsi tulemused;
o Ukraina ja teiste riikide auditeeritava ettevõtte ja sarnaste ettevõtete keskkonna- ja tootmistegevuse põhinäitajate võrdleva analüüsi tulemused;
o hinnang auditeeritava ettevõtte võimalikule ohule hädaolukorras, väljatöötatud tööplaani tulemuslikkusele õnnetuse allika likvideerimiseks, vajalike materiaal-tehniliste vahendite olemasolule;
o järeldus ettevõtte keskkonnateenistuste töötajate erialase pädevuse kohta, nende varustamise kaasaegsete tehniliste vahenditega lubatavate saastetasemete järgimise kontrollimiseks;
o juhtkonna ja tootmispersonali teadlikkus oma ettevõtte keskkonnasaaste suurusest ja olemusest, materiaalsete ja moraalsete stiimulite olemasolust saastetaseme ning toodetavate toodete energia- ja materjalimahukuse vähendamiseks.
Keskkonnaaudiitori järeldusele tuginedes saab konkreetset probleemi (näiteks teatud saastava koostisosa koguse või kontsentratsiooni vähendamist) lahendada erinevate, sageli alternatiivsete meetoditega. Olenevalt tehtud otsuse radikaalsusest ja probleemi tõsidusest võivad vajalikud keskkonnakaitsemeetmed ulatuda organisatsioonilistest meetmetest ja suuremast kontrollist tehnoloogilise protsessi ja keskkonnakaitseseadmete töö üle kuni ettevõtte sulgemiseni koos selle hilisema ümbersuunamisega. .
Üks oluline EA arengut maailmas soodustav tegur on programmi rakendamise kord. Keskkonnaauditite läbiviimise protsessis on vastutajate väljaselgitamine ja karistamine kaugel peamisest eesmärgist. Ettevõtte juhtkonna jaoks on palju olulisem tuvastada objekti kõikides tegevusvaldkondades kitsaskohad, millel on ühel või teisel määral negatiivne mõju keskkonnale, ja aidata kaasa selle vähendamisele. Objektiivse uuringu läbiviimine on võimatu ilma tiheda koostööta ettevõtte administratsiooni ja tootmispersonaliga, s.o. muutmata seda kontrollitavast isikust täispartneriks, kelle arvamust ja argumentatsiooni arvestatakse kõikides EA etappides.
EA hoiatab olukorra eest, kus keskkonnaprobleemid puudutavad vaid ettevõtte juhtkonda, kes on sunnitud omal vastutusel varjama tootmistegevuse negatiivseid tagajärgi nii kaugele, et nende varjamine muutub võimatuks ja nende kõrvaldamine toob kaasa õiguslikud tagajärjed. menetlused ja sanktsioonid. Selleks on soovitav kaasata konkreetse ettevõtte keskkonnaprobleemide lahendamisse piirkonna teaduspotentsiaal, keskkonnateenistuste töötajad ja finantsasutused.
Maailmapanga hinnangul tasub keskkonnamõjude hindamise ja hilisema keskkonnapiirangute arvestamisega kaasnev projektikulude võimalik tõus end ära keskmiselt 5-7 aastaga. Keskkonnategurite kaasamine otsustusprotsessi projekteerimisetapis on 3-4 korda odavam kui hilisem täiendavate puhastusseadmete paigaldamine ning mitteökoloogilise tehnoloogia ja seadmete kasutamise tagajärgede likvideerimise kulud on 30-35 korda suuremad kulutused, mis oleksid vajalikud keskkonnasõbraliku lahenduse väljatöötamiseks.puhas tehnoloogia ja keskkonnasäästlike seadmete kasutamine.
Kõikide huvitatud osapoolte arvamusi arvestav keskkonnaauditeeritud ettevõtte igakülgse mõju keskkonnaseisundile objektiivne uuring aitab vältida keskkonna- ja majanduskriisi edasist süvenemist ning määrata kindlaks keskkonna- ja majanduskriisi arvestamise viisid. keskkonnategur majandustegevuse strateegiate ja taktikate väljatöötamisel. See suurendab ettevõtte tööstusohutust ja seega ka investeerimisatraktiivsust.
Olulisuse näitajate määramine gradiendi abil
Kahekordne toimiv närvivõrk suudab sisendsignaalide ja võrgu treenitavate parameetrite põhjal arvutada hindamisfunktsiooni gradiendi.
Parameetri olulisuse indikaatoriks q-o näite lahendamisel on väärtus, mis näitab, kui palju muutub q-o näite võrgu poolt lahenduse hindamise funktsiooni väärtus, kui parameetri w p praegune väärtus asendatakse valitud väärtusega. väärtus w p . Selle täpse väärtuse saab määrata asenduste tegemise ja võrgu hinnangu arvutamise teel. Arvestades võrguparameetrite suurt hulka, võtab kõigi parameetrite olulisuse näitajate arvutamine aga palju aega. Olulisuse parameetrite hindamise protsessi kiirendamiseks kasutatakse täpsete väärtuste asemel erinevaid hinnanguid. Vaatleme kõige lihtsamat ja enimkasutatavat olulisuse näitajate lineaarset hindamist. Laiendame hindamisfunktsiooni Taylori seeriaks kuni esimest järku terminiteni:
kus H 0 q on hindamisfunktsiooni väärtus q-o näite lahendusel w =w. Seega määratakse p-o parameetri olulisuse indikaator q-o näite lahendamisel järgmise valemiga:
Olulisuse indikaatorit (1) saab arvutada erinevate objektide jaoks. Kõige sagedamini arvutatakse see koolitatavate võrguparameetrite jaoks. Tüüpi (1) olulisuse indikaator on aga rakendatav ka signaalide puhul. Nagu peatükis juba märgitud, arvutab võrk tagurpidi töötades alati kaks gradiendivektorit - hindamisfunktsiooni gradiendi koolitatud võrguparameetrite ja kõigi võrgusignaalide põhjal. Kui olulisuse skoor arvutatakse kõige vähem olulise neuroni tuvastamiseks, tuleks arvutada neuroni väljundi olulisuse skoor. Samamoodi on vähima tähtsusega sisendsignaali määramise ülesandes vaja arvutada selle signaali olulisus, mitte nende ühenduste kaalude olulisuse summa, millele see signaal rakendatakse.
Treeningkomplekti keskmine
Parameetri X q p olulisuse indikaator sõltub parameetriruumi punktist, kus see arvutatakse, ja näitest treeningkomplektist. Näitest mittesõltuva parameetri olulisuse indikaatori saamiseks on kaks põhimõtteliselt erinevat lähenemist. Esimese lähenemisviisi puhul eeldatakse, et koolituskomplekt sisaldab täielikku teavet kõigi võimalike näidete kohta. Sel juhul mõistetakse olulisuse indikaatori all väärtust, mis näitab, kui palju muutub koolituskomplekti hindamisfunktsiooni väärtus, kui parameetri w p praegune väärtus asendatakse valitud väärtusega w p . See väärtus arvutatakse järgmise valemi abil:
Teise lähenemisviisi korral käsitletakse treeningkomplekti juhusliku valimina sisendparameetrite ruumis. Sel juhul on kogu treeningkomplekti olulisuse näitaja treeningkomplekti mõne keskmistamise tulemus.
Keskmistamise meetodeid on palju. Vaatame neist kahte. Kui keskmistamise tulemusena peaks olulisuse näitaja andma keskmise olulisuse, arvutatakse selline näitaja järgmise valemi abil:
Kui keskmistamise tulemusena peaks olulisuse näitaja andma väärtuse, mis ei ületa üksikute näidete olulisuse näitajaid (selle parameetri olulisus üksiknäite puhul ei ületa O§ p), siis selline näitaja arvutatakse. kasutades järgmist valemit:
Olulisuse näitajate kuhjumine
Kõik olulisuse indikaatorid sõltuvad võrgu parameetrite ruumi punktist, kus neid arvutatakse, ja võivad ühest punktist teise liikumisel oluliselt erineda. Gradiendi abil arvutatud olulisusindeksite puhul on see sõltuvus veelgi tugevam, kuna järseima laskumise meetodil (vt jaotist ) treenimisel parameetriruumi kahes kõrvuti asetsevas punktis, kus gradient arvutati, on gradiendid ortogonaalsed. Ruumipunktist sõltuvuse eemaldamiseks kasutatakse mitmes punktis arvutatud olulisuse näitajaid. Järgmisena arvutatakse need keskmised, kasutades valemeid (3) ja (4). Parameetriruumi punktide valimise küsimus olulisuse näitajate arvutamiseks lahendatakse tavaliselt lihtsalt. Mis tahes gradiendimeetodi mitme koolitusetapi jooksul arvutatakse iga kord, kui gradient arvutatakse, ka olulisuse hinded. Õppesammude arv, mille jooksul olulisuse näitajaid kogutakse, ei tohiks olla liiga suur, kuna suure õppesammude arvu korral muutuvad esimesed arvutatud olulisuse näitajad mõttetuks, eriti kui kasutada keskmistamist valemi (4) järgi.
Kirjanduse analüüsi ja NeuroComp grupi kogemuste põhjal saame sõnastada järgmised ülesanded, mida saab lahendada kontrastsete närvivõrkude abil.
1. Närvivõrgu arhitektuuri lihtsustamine.
2. Sisendsignaalide arvu vähendamine.
3. Närvivõrgu parameetrite taandamine väikesele valitud väärtuste hulgale.
4. Vähendatud nõuded sisendsignaalide täpsusele.
5. Andmete põhjal selgesõnaliste teadmiste saamine.
Selles peatükis käsitletud kontrasti algoritmid võimaldavad meil valida minimaalse nõutava sisendsignaalide komplekti. Minimaalse sisendsignaalide komplekti kasutamine võimaldab säästlikumalt korraldada närviarvuti tööd. Kuid minimaalsel komplektil on oma puudused. Kuna komplekt on minimaalne, ei toetata tavaliselt ühe signaali edastatavat teavet teised sisendsignaalid. See toob kaasa asjaolu, et kui ühes sisendsignaalis on viga, eksib võrk suure tõenäosusega. Liigse sisendsignaalide komplekti korral seda tavaliselt ei juhtu, kuna iga signaali teavet tugevdavad (dubleerivad) teised signaalid.
Seega tekib vastuolu - esialgse üleliigse signaalikomplekti kasutamine on ebaökonoomne ja minimaalse signaalikomplekti kasutamine toob kaasa suurenenud vigade riski. Sellises olukorras on õige kompromisslahendus - on vaja leida minimaalne komplekt, milles kogu teave dubleeritakse. Selles jaotises käsitletakse meetodeid selliste suurema usaldusväärsusega komplektide koostamiseks. Lisaks võimaldab teist tüüpi duplikaatide ehitamine määrata, millistel sisendsignaalidel pole algses signaalikomplektis duplikaate. Sellise "unikaalse" signaali kaasamine miinimumkomplekti on signaal, et kui kasutate selle probleemi lahendamiseks närvivõrku, peaksite hoolikalt jälgima selle signaali väärtuse õigsust.
Kontrastimisprotseduure on kahte tüüpi – parameetrite olulisusel põhinev kontrastimine ja mittealandav kontrastimine. Selles jaotises kirjeldatakse mõlemat tüüpi kontrastaineprotseduure.
Selles jaotises kirjeldatakse meetodit parameetrite ja signaalide olulisuse näitajate määramiseks. Järgmisena räägime parameetrite olulisuse määramisest. Võrgusignaalide olulisuse näitajad määratakse samade valemite abil, mille parameetrid on asendatud signaalidega.