特性間の確率的関係を研究する方法の 1 つは回帰分析です。
回帰分析は、別の変数 (因子属性) の値がわかっている場合に、これを利用して確率変数 (結果属性) の平均値を求める回帰方程式の導出です。 これには次の手順が含まれます。
- 接続の形式 (分析回帰式の種類) の選択。
- 方程式パラメータの推定。
- 分析回帰式の品質の評価。
線形ペア関係の場合、回帰方程式は y i =a+b・x i +u i の形式になります。 この式のパラメータ a と b は、統計的な観測データ x と y から推定されます。 このような評価の結果は次の方程式になります。 ここで、 はパラメータ a および b の推定値であり、 は回帰式から得られる結果の属性 (変数) の値 (計算値) です。
パラメータを推定するために最もよく使用されます 最小二乗法 (LSM)。
最小二乗法は、回帰式のパラメータの最適な (一貫性があり、効率的で、不偏の) 推定値を提供します。 ただし、ランダム項 (u) と独立変数 (x) に関する特定の仮定が満たされている場合に限ります (OLS の仮定を参照)。
最小二乗法を使用して線形対方程式のパラメータを推定する問題は次のとおりです。計算値から得られる特性の実際の値 - y i - の二乗偏差の合計が最小となるパラメータの推定値 、 を取得します。
正式には OLSテスト次のように書くことができます:  .
.
最小二乗法の分類
- 最小二乗法。
- 最尤法 (通常の古典的線形回帰モデルの場合、回帰残差の正規性が仮定されます)。
- 一般化最小二乗 OLS 法は、誤差の自己相関の場合と不均一分散の場合に使用されます。
- 重み付き最小二乗法 (不均一分散残差を持つ OLS の特殊なケース)。
要点を説明しましょう グラフィックによる古典的な最小二乗法。 これを行うために、観測データ (x i, y i, i=1;n) に基づいて直交座標系で散布図を作成します (このような散布図は相関場と呼ばれます)。 相関フィールドの点に最も近い直線を選択してみましょう。 最小二乗法によれば、相関フィールドの点とこの直線の間の垂直距離の二乗和が最小になるように直線が選択されます。 
この問題の数学的表記:  .
.
y i と x i =1...n の値は既知です。これらは観測データです。 S 関数では、これらは定数を表します。 この関数の変数は、パラメーターの必要な推定値です ( 、 、 )。 2 つの変数の関数の最小値を見つけるには、各パラメーターについてこの関数の偏導関数を計算し、それらをゼロに等しくする必要があります。 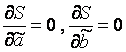 .
.
その結果、2 つの正規一次方程式からなる系が得られます。 
このシステムを解くと、必要なパラメーターの推定値がわかります。 
回帰式のパラメータの計算が正しいかどうかは、金額を比較することで確認できます(計算の四捨五入により多少の誤差が生じる場合があります)。
パラメーターの推定値を計算するには、表 1 を作成します。
回帰係数 b の符号は、関係の方向を示します (b >0 の場合、関係は直接的であり、b の場合)。<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
正式には、パラメータ a の値は、x が 0 に等しい y の平均値です。 属性因子がゼロ値を持たず、ゼロ値を持つことができない場合、パラメータ a の上記の解釈は意味を持ちません。
特性間の関係の近さを評価する
線形ペア相関係数 - r x,y を使用して実行されます。 次の式を使用して計算できます。  。 さらに、線形ペアの相関係数は回帰係数 b を通じて決定できます。
。 さらに、線形ペアの相関係数は回帰係数 b を通じて決定できます。  .
.
線形ペア相関係数の許容値の範囲は –1 ~ +1 です。 相関係数の符号は、関係の方向を示します。 r x, y >0 の場合、接続は直接です。 r x、y の場合<0, то связь обратная.
この係数の大きさが 1 に近い場合、特性間の関係はかなり線形に近いものとして解釈できます。 そのモジュールが 1 ê r x , y ê =1 に等しい場合、特性間の関係は関数線形です。 特徴 x と y が線形独立している場合、r x,y は 0 に近づきます。
r x,y を計算するには、表 1 を使用することもできます。
結果として得られる回帰式の品質を評価するには、理論的な決定係数 - R 2 yx を計算します。  ,
,
ここで、d 2 は回帰式で説明される y の分散です。
e 2 - y の残差 (回帰式では説明できない) 分散。
s 2 y - y の合計 (合計) 分散。
決定係数は、全体の変動 (分散) y における、回帰 (したがって係数 x) によって説明される、結果として得られる属性 y の変動 (分散) の割合を特徴付けます。 決定係数 R 2 yx は 0 から 1 までの値を取ります。 したがって、値 1-R 2 yx は、モデルおよび仕様誤差で考慮されていない他の要因の影響によって引き起こされる分散 y の割合を特徴付けます。
一対の線形回帰では、R 2 yx =r 2 yx となります。
回帰関数のタイプを選択したら、つまり Y と X (または X と Y) の依存性を考慮したモデルのタイプ (たとえば、線形モデル y x =a+bx)、モデル係数の特定の値を決定する必要があります。
a と b の値が異なる場合、y x = a + bx の形式の依存関係を無限に構築することが可能です。つまり、座標平面上には直線が無限にありますが、最適な依存関係が必要です。観測値と一致します。 したがって、タスクは最適な係数を選択することになります。
特定の数の利用可能な観測値のみに基づいて、線形関数 a+bx を探します。 観測値に最もよく適合する関数を見つけるには、最小二乗法を使用します。
Y i - 方程式 Y i =a+bx i によって計算された値。 y i - 測定値、ε i =y i -Y i - 方程式、ε i =y i -a-bx i を使用した測定値と計算値の差。
最小二乗法では、測定された y i と式から計算された値 Y i の差である ε i が最小限であることが必要です。 したがって、直線回帰直線上の値からの観測値の偏差の二乗の合計が最小になるように係数 a と b を求めます。
この引数 a の関数と導関数を使用した極値を調べることにより、係数 a と b がシステムの解である場合、関数が最小値をとることを証明できます。
 (2)
(2)
正規方程式の両辺を n で割ると、次のようになります。

それを考えると  (3)
(3)
我々が得る  ここから、最初の方程式に a の値を代入すると、次のようになります。
ここから、最初の方程式に a の値を代入すると、次のようになります。

この場合、b は回帰係数と呼ばれます。 a は回帰式の自由項と呼ばれ、次の式を使用して計算されます。
結果として得られる直線は、理論的な回帰直線の推定値です。 我々は持っています:
それで、 ![]() は線形回帰式です。
は線形回帰式です。
回帰には、直接 (b>0) と逆回帰 (b 例 1) があります。X と Y の値の測定結果を表に示します。
| x i | -2 | 0 | 1 | 2 | 4 |
| はい、私 | 0.5 | 1 | 1.5 | 2 | 3 |
X と Y の間に線形関係 y=a+bx があると仮定し、最小二乗法を使用して係数 a と b を決定します。
解決。 ここで n=5
x i =-2+0+1+2+4=5;
x i 2 =4+0+1+4+16=25
x i y i =-2 0.5+0 1+1 1.5+2 2+4 3=16.5
y i =0.5+1+1.5+2+3=8
正規系 (2) は次の形式になります。 ![]()
この系を解くと、b=0.425、a=1.175 が得られます。 したがって、y=1.175+0.425xとなります。
例 2. 経済指標 (X) および (Y) の 10 個の観測値のサンプルがあります。
| x i | 180 | 172 | 173 | 169 | 175 | 170 | 179 | 170 | 167 | 174 |
| はい、私 | 186 | 180 | 176 | 171 | 182 | 166 | 182 | 172 | 169 | 177 |
X に対する Y の標本回帰式を見つける必要があります。X に対する Y の標本回帰直線を作成します。
解決。 1. 値 x i と y i に従ってデータを並べ替えましょう。 新しいテーブルを取得します。
| x i | 167 | 169 | 170 | 170 | 172 | 173 | 174 | 175 | 179 | 180 |
| はい、私 | 169 | 171 | 166 | 172 | 180 | 176 | 177 | 182 | 182 | 186 |
計算を簡略化するために、必要な数値を入力する計算表を作成します。
| x i | はい、私 | x i 2 | x i y i |
| 167 | 169 | 27889 | 28223 |
| 169 | 171 | 28561 | 28899 |
| 170 | 166 | 28900 | 28220 |
| 170 | 172 | 28900 | 29240 |
| 172 | 180 | 29584 | 30960 |
| 173 | 176 | 29929 | 30448 |
| 174 | 177 | 30276 | 30798 |
| 175 | 182 | 30625 | 31850 |
| 179 | 182 | 32041 | 32578 |
| 180 | 186 | 32400 | 33480 |
| ∑x i =1729 | ∑y i =1761 | ∑x i 2 299105 | ∑x i y i =304696 |
| x=172.9 | y=176.1 | x i 2 =29910.5 | xy=30469.6 |
式(4)に従って、回帰係数を計算します。
そして式(5)によると
したがって、サンプル回帰式は y=-59.34+1.3804x となります。
座標平面上に点 (x i ; y i) をプロットし、回帰直線をマークしましょう。

図4
図 4 は、観測値が回帰直線に対してどのように配置されるかを示しています。 Y i からの y i の偏差を数値的に評価するために、y i は観測され、Y i は回帰によって決定された値です。次の表を作成します。
| x i | はい、私 | やあ | Y i -y i |
| 167 | 169 | 168.055 | -0.945 |
| 169 | 171 | 170.778 | -0.222 |
| 170 | 166 | 172.140 | 6.140 |
| 170 | 172 | 172.140 | 0.140 |
| 172 | 180 | 174.863 | -5.137 |
| 173 | 176 | 176.225 | 0.225 |
| 174 | 177 | 177.587 | 0.587 |
| 175 | 182 | 178.949 | -3.051 |
| 179 | 182 | 184.395 | 2.395 |
| 180 | 186 | 185.757 | -0.243 |
Yi値は回帰式に従って計算されます。
一部の観測値が回帰直線から顕著に乖離しているのは、観測値の少なさによって説明されます。 X に対する Y の線形依存性の程度を調べるときは、観測値の数が考慮されます。 依存関係の強さは相関係数の値によって決まります。
実験データの近似は、実験で得られたデータを、節点で元の値(実験または実験中に得られたデータ)に最も近く通過または一致する解析関数で置き換えることに基づく方法です。 現在、分析関数を定義するには 2 つの方法があります。
次のような n 次の補間多項式を構築することによって、 すべてのポイントを直接経由して指定されたデータ配列。 この場合、近似関数は、ラグランジュ形式の補間多項式またはニュートン形式の補間多項式の形式で表されます。
次のような n 次の近似多項式を構築することによって、 ポイントのすぐ近くにある指定されたデータ配列から。 したがって、近似関数は、実験中に発生する可能性のあるすべてのランダム ノイズ (または誤差) を平滑化します。実験中の測定値は、独自のランダム法則 (測定または機器の誤差、不正確さ、または実験的な誤差) に従って変動するランダムな要因に依存します。エラー)。 この場合、近似関数は最小二乗法を用いて決定される。
最小二乗法(英語の文献では Ordinary Least Squares、OLS) は、与えられた実験データの配列からの点に最も近い近似関数の決定に基づく数学的手法です。 元の関数と近似関数 F(x) の近さは数値的な尺度によって決定されます。つまり、近似曲線 F(x) からの実験データの偏差の二乗の合計が最小になるはずです。
最小二乗法で作成した近似曲線
最小二乗法が使用されます。
方程式の数が未知数の数を超える場合に、過剰決定された連立方程式を解くため。
通常の (過剰決定ではない) 非線形方程式系の場合の解を見つける。
何らかの近似関数を使用してポイント値を近似する。
最小二乗法を使用した近似関数は、与えられた一連の実験データから計算された近似関数の偏差二乗和の最小値の条件から決定されます。 最小二乗法のこの基準は次の式で表されます。

計算された節点における近似関数の値、
節点における実験データの所定の配列。
二次基準には微分可能性などの多くの「優れた」特性があり、多項式近似関数による近似問題に対する独自の解決策を提供します。
問題の条件に応じて、近似関数は m 次の多項式になります。
近似関数の次数は節点の数には依存しませんが、その次元は常に、特定の実験データ配列の次元 (点の数) より小さくなければなりません。
![]()
・近似関数の次数が m=1 の場合、表関数を直線で近似します (線形回帰)。
・近似関数の次数が m=2 の場合、テーブル関数を 2 次放物線で近似します (2 次近似)。
・近似関数の次数が m=3 の場合、テーブル関数を 3 次放物線で近似します (3 次近似)。
一般的なケースでは、与えられたテーブル値に対して次数 m の近似多項式を構築する必要がある場合、すべての節点にわたる偏差の二乗和の最小値の条件は次の形式で書き換えられます。
![]() - m 次の近似多項式の未知の係数。
- m 次の近似多項式の未知の係数。
指定されたテーブル値の数。
関数の最小値が存在するための必要な条件は、未知の変数に関するその偏導関数がゼロに等しいことです。 ![]() 。 その結果、次の連立方程式が得られます。
。 その結果、次の連立方程式が得られます。

結果として得られる線形方程式系を変換してみましょう。括弧を開いて自由項を式の右側に移動します。 その結果、線形代数式の系は次の形式で記述されます。

この線形代数式系は行列形式で書き直すことができます。

その結果、m+1 個の未知数からなる m+1 次元の線形方程式系が得られました。 この系は、線形代数方程式を解くための任意の方法 (ガウス法など) を使用して解くことができます。 解法の結果として、元のデータからの近似関数の偏差の二乗和の最小値を与える近似関数の未知のパラメーターが見つかります。 可能な限り最良の二次近似。 ソース データの値が 1 つでも変更されると、すべての係数の値が変更されることに注意してください。これは、係数はソース データによって完全に決定されるためです。
線形依存性によるソースデータの近似
(線形回帰)
例として、線形依存の形式で指定される近似関数を決定する手法を考えてみましょう。 最小二乗法に従って、偏差二乗和の最小値の条件は次の形式で記述されます。
テーブルノードの座標。
近似関数の未知の係数。線形依存として指定されます。
関数の最小値が存在するための必要な条件は、未知の変数に関するその偏導関数がゼロに等しいことです。 その結果、次の連立方程式が得られます。

結果として得られる線形方程式系を変換してみましょう。

結果として得られる連立一次方程式を解きます。 分析形式の近似関数の係数は次のように決定されます (Cramer の方法)。

これらの係数は、指定された表の値 (実験データ) から近似関数の二乗和を最小化する基準に従って線形近似関数を構築することを保証します。
最小二乗法を実装するためのアルゴリズム
1. 初期データ:
測定数 N の実験データの配列が指定されます
近似多項式の次数(m)を指定します
2. 計算アルゴリズム:
2.1. 係数は、次元を持つ方程式系を構築するために決定されます。

連立方程式の係数 (方程式の左側)
![]()
![]() - 連立方程式の正方行列の列番号のインデックス
- 連立方程式の正方行列の列番号のインデックス

連立一次方程式の自由項 (方程式の右辺)
![]() - 連立方程式の正方行列の行番号のインデックス
- 連立方程式の正方行列の行番号のインデックス
2.2. 次元 の線形方程式系の形成。

2.3. 連立一次方程式を解いて、m 次の近似多項式の未知の係数を決定します。
2.4. すべての節点における元の値からの近似多項式の偏差の二乗和の決定

求められた偏差の二乗和の値は可能な最小値です。
他の関数を用いた近似
なお、最小二乗法により元データを近似する場合、近似関数として対数関数、指数関数、べき乗関数が用いられることがある。
対数近似
近似関数が次の形式の対数関数で与えられる場合を考えてみましょう。
3. この方法を使用した関数の近似
最小二乗
最小二乗法は、実験結果を処理するときに使用されます。 近似 (近似値) 実験データ 分析式。 特定の種類のフォーミュラは、原則として物理的な理由から選択されます。 そのような式は次のようになります。
![]()
![]()
その他。
最小二乗法の本質は次のとおりです。 測定結果を表に示します。
|
テーブル 4 |
||||
|
×n |
||||
|
yn |
||||
|
(3.1) |
ここで、f - 既知の機能、 a 0 、a 1 、…、a m - 値を見つける必要がある未知の定数パラメータ。 最小二乗法では、条件が満たされる場合、関数 (3.1) の実験依存性への近似が最適であると見なされます。
|
(3.2) |
あれは 金額 ある 実験依存性からの所望の分析関数の二乗偏差は最小限でなければなりません .
関数に注意してください Q 呼ばれた 残留物。

齟齬があったので、

その場合は最小値があります。 いくつかの変数の関数を最小にするために必要な条件は、パラメーターに関するこの関数のすべての偏導関数がゼロに等しいことです。 したがって、近似関数 (3.1) のパラメータの最適な値、つまり、次の値が得られる値を見つけます。 Q = Q (a 0 , a 1 , …, a m ) は最小限であり、連立方程式を解くことに帰着します。
|
(3.3) |
最小二乗法には、次のような幾何学的な解釈が与えられます。指定されたタイプの無限のライン群の中から、実験点の縦座標と対応する点の縦座標の差の二乗の合計が求められる 1 つのラインが見つかります。この直線の方程式により が最小になります。
一次関数のパラメータを求める
実験データを一次関数で表すとします。
次の値を選択する必要があります aとb 、その関数
|
(3.4) |
最小限になります。 関数 (3.4) の最小値に必要な条件は、次の連立方程式に帰着します。
|
|

変換後、2 つの未知数を含む 2 つの線形方程式系が得られます。
|
|
(3.5) |

これを解決すると、パラメータの必要な値が見つかります aとb。
二次関数のパラメータを求める
近似関数が二次依存の場合
次にそのパラメータ a、b、c 関数の最小条件から求められます。
|
(3.6) |
関数 (3.6) の最小値の条件は、次の連立方程式に帰着します。
|
|

変換後、3 つの未知数を含む 3 つの線形方程式系が得られます。
|
|
(3.7) |

で パラメーターの必要な値を見つけるソリューション a、b、c。
例 。 実験結果が次の値表になるとします。 x と y:
|
テーブル 5 |
||||||||
|
はい、私 |
0,705 |
0,495 |
0,426 |
0,357 |
0,368 |
0,406 |
0,549 |
0,768 |
実験データを一次関数および二次関数で近似する必要があります。
解決。 近似関数のパラメータを見つけることは、連立一次方程式 (3.5) および (3.7) を解くことに帰着します。 この問題を解決するには、スプレッドシート プロセッサを使用します。エクセル。
1. まずはシート1とシート2を接続しましょう。実験値を入力します x私と はい、私列に入れる A と B、2 行目から開始します (列見出しは 1 行目に配置します)。 次に、これらの列の合計を計算し、10 行目に配置します。
C列~G列 計算と合計をそれぞれ配置します
2. シートを分離しましょう。シート 1 の線形依存性とシート 2 の二次依存性についても同様の方法でさらに計算を実行します。
3. 結果のテーブルの下で、係数の行列と自由項の列ベクトルを形成します。 次のアルゴリズムを使用して連立一次方程式を解いてみましょう。
逆行列と乗算行列を計算するには、次を使用します。 マスター 機能と機能 モブラそして マムニット.
4. セル H2 のブロック内: H 9 得られた係数に基づいて計算します 近似値多項式はい、私 計算する.、ブロック I 2: I 9 – 偏差 ダイアイ = はい、私 経験値. - はい、私 計算する.,列 J – 残差:
結果として得られるテーブルと、次を使用して構築されたテーブル チャートウィザードグラフを図 6、7、8 に示します。

米。 6. 一次関数の係数を計算するための表、
近似する実験データ。

米。 7. 二次関数の係数を計算するためのテーブル、
近似する実験データ。

米。 8. 近似結果のグラフ表示
一次関数と二次関数による実験データ。
答え。 実験データは線形依存性によって近似されました y = 0,07881 バツ + 0,442262 残留物あり Q = 0,165167 と二次依存性 y = 3,115476 バツ 2 – 5,2175 バツ + 2,529631 残留物あり Q = 0,002103 .
タスク。 テーブルで与えられる関数、一次関数、二次関数を近似します。
|
表6 |
|||||||||
|
№0 |
バツ |
0,1 |
0,2 |
0,3 |
0,4 |
0,5 |
0,6 |
0,7 |
0,8 |
|
y |
3,030 |
3,142 |
3,358 |
3,463 |
3,772 |
3,251 |
3,170 |
3,665 |
|
|
№ 1 |
|||||||||
|
3,314 |
3,278 |
3,262 |
3,292 |
3,332 |
3,397 |
3,487 |
3,563 |
||
|
№ 2 |
|||||||||
|
1,045 |
1,162 |
1,264 |
1,172 |
1,070 |
0,898 |
0,656 |
0,344 |
||
|
№ 3 |
|||||||||
|
6,715 |
6,735 |
6,750 |
6,741 |
6,645 |
6,639 |
6,647 |
6,612 |
||
|
№ 4 |
|||||||||
|
2,325 |
2,515 |
2,638 |
2,700 |
2,696 |
2,626 |
2,491 |
2,291 |
||
|
№ 5 |
|||||||||
|
1.752 |
1,762 |
1,777 |
1,797 |
1,821 |
1,850 |
1,884 |
1,944 |
||
|
№ 6 |
|||||||||
|
1,924 |
1,710 |
1,525 |
1,370 |
1,264 |
1,190 |
1,148 |
1,127 |
||
|
№ 7 |
|||||||||
|
1,025 |
1,144 |
1,336 |
1,419 |
1,479 |
1,530 |
1,568 |
1,248 |
||
|
№ 8 |
|||||||||
|
5,785 |
5,685 |
5,605 |
5,545 |
5,505 |
5,480 |
5,495 |
5,510 |
||
|
№ 9 |
|||||||||
|
4,052 |
4,092 |
4,152 |
4,234 |
4,338 |
4,468 |
4,599 |
最小二乗法 (OLS) を使用すると、ランダム誤差を含む多くの測定結果を使用して、さまざまな量を推定できます。 多国籍企業の特徴 この方法の主な考え方は、誤差の二乗和を問題解決の精度の基準として考慮し、それを最小限に抑えるよう努めることです。 この方法を使用する場合、数値的アプローチと分析的アプローチの両方を使用できます。 特に、数値的な実装として、最小二乗法には、未知の確率変数のできるだけ多くの測定値を取得することが含まれます。 さらに、計算が多ければ多いほど、解の精度は高くなります。 この一連の計算 (初期データ) に基づいて、別の一連の推定解が取得され、そこから最適な解が選択されます。 一連の解がパラメータ化されている場合、最小二乗法はパラメータの最適値を見つけることに帰着します。 初期データ (測定値) のセットと予想される解のセットに対する LSM の実装に対する分析的アプローチとして、特定のデータ (関数) が決定されます。これは、確認を必要とする特定の仮説として得られる式で表すことができます。 この場合、最小二乗法は、元のデータの二乗誤差のセットでこの関数の最小値を見つけることになります。 誤差そのものではなく、誤差の二乗であることに注意してください。 なぜ? 実際のところ、正確な値からの測定値の偏差はプラスにもマイナスにもなることがよくあります。 平均を求める場合、正と負の値をキャンセルすると複数の測定値をサンプリングする能力が低下するため、単純な合計は推定の品質について誤った結論につながる可能性があります。 そして、結果として評価の精度も高まります。 これを防ぐために、偏差の 2 乗が合計されます。 さらに、測定値と最終推定値の次元を一致させるために、誤差の二乗和を抽出します。 MNC のいくつかのアプリケーション MNCはさまざまな分野で広く使用されています。 たとえば、確率理論や数学的統計では、この方法は、確率変数の値の範囲の幅を決定する標準偏差などの確率変数の特性を決定するために使用されます。 類似記事
| ||



