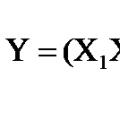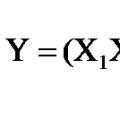Bir sonucun istatistiksel anlamlılığı (p-değeri), onun “doğruluğuna” (“örneklemin temsil edilebilirliği” anlamında) olan güvenin tahmini bir ölçüsüdür. Daha teknik konuşursak, p değeri, sonucun güvenilirliğine göre azalan büyüklük sırasına göre değişen bir ölçüdür. Daha yüksek bir p değeri, örnekte bulunan değişkenler arasındaki ilişkide daha düşük bir güven düzeyine karşılık gelir. Spesifik olarak p değeri, gözlemlenen sonucun tüm popülasyona genelleştirilmesiyle ilişkili hata olasılığını temsil eder. Örneğin, 0,05'lik bir p değeri (yani 1/20), numunede bulunan değişkenler arasındaki ilişkinin numunenin yalnızca rastgele bir özelliği olma ihtimalinin %5 olduğunu gösterir. Başka bir deyişle, bir popülasyonda belirli bir ilişki mevcut değilse ve benzer deneyleri birçok kez yaparsanız, o zaman deneyin yaklaşık yirmi tekrarından birinde değişkenler arasında aynı veya daha güçlü bir ilişki olmasını beklersiniz.
Birçok çalışmada hata düzeyi için 0,05'lik bir p değeri "kabul edilebilir marj" olarak kabul edilir.
Hangi önem düzeyinin gerçekten "önemli" olarak kabul edilmesi gerektiğine karar verirken keyfilikten kaçınmanın bir yolu yoktur. Üzerinde sonuçların yanlış olarak reddedildiği belirli bir anlamlılık düzeyinin seçimi oldukça keyfidir. Uygulamada, nihai karar genellikle sonucun önceden mi tahmin edildiğine (yani deney gerçekleştirilmeden önce) veya çeşitli veriler üzerinde yapılan birçok analiz ve karşılaştırmanın bir sonucu olarak sonradan mı keşfedildiğine bağlıdır. çalışma alanının geleneği. Tipik olarak birçok alanda p 0,05 sonucu, istatistiksel anlamlılık açısından kabul edilebilir bir sınırdır, ancak bu düzeyin hala oldukça büyük bir hata oranı (%5) içerdiği unutulmamalıdır. p 0,01 düzeyinde anlamlı olan sonuçlar genellikle istatistiksel olarak anlamlı kabul edilir ve p 0,005 veya p 0,001 düzeyindeki sonuçlar genellikle oldukça anlamlı kabul edilir. Bununla birlikte, bu önem düzeyi sınıflandırmasının oldukça keyfi olduğu ve yalnızca belirli bir araştırma alanındaki pratik deneyime dayanarak kabul edilen resmi olmayan bir anlaşma olduğu anlaşılmalıdır.
Daha önce de belirtildiği gibi ilişkinin büyüklüğü ve güvenirlik, değişkenler arasındaki ilişkinin iki farklı özelliğini temsil etmektedir. Ancak tamamen bağımsız oldukları söylenemez. Genel olarak konuşursak, normal büyüklükteki bir örneklemde değişkenler arasındaki ilişkinin (ilişkinin) büyüklüğü ne kadar büyük olursa, o kadar güvenilir olur.
Eğer popülasyonda karşılık gelen değişkenler arasında bir ilişki olmadığını varsayarsak, o zaman incelenen örnekte de bu değişkenler arasında bir ilişkinin olmayacağını beklemek büyük olasılıkla muhtemeldir. Bu nedenle, bir örnekte ne kadar güçlü bir ilişki bulunursa, ilişkinin alındığı popülasyonda var olmama olasılığı da o kadar az olur.
Örneklem büyüklüğü ilişkinin önemini etkiler. Az sayıda gözlem varsa, o zaman bu değişkenler için buna uygun olarak az sayıda olası değer kombinasyonu vardır ve bu nedenle, güçlü bir ilişki gösteren bir değer kombinasyonunun kazara keşfedilme olasılığı nispeten yüksektir.
İstatistiksel anlamlılık düzeyi nasıl hesaplanır? İki değişken arasındaki bağımlılığın ölçüsünü zaten hesapladığınızı varsayalım (yukarıda açıklandığı gibi). Karşılaştığınız bir sonraki soru şudur: "Bu ilişki ne kadar önemli?" Örneğin, iki değişken arasındaki açıklanan varyansın %40'ı ilişkinin anlamlı olduğunu düşünmek için yeterli midir? Cevap: "Durumlara göre." Yani anlamlılık esas olarak örneklem büyüklüğüne bağlıdır. Daha önce açıklandığı gibi, çok büyük örneklemlerde değişkenler arasındaki çok zayıf ilişkiler bile anlamlı olurken, küçük örneklemlerde çok güçlü ilişkiler bile güvenilir değildir. Bu nedenle, istatistiksel anlamlılık düzeyini belirlemek amacıyla, her örnek boyutu için değişkenler arasındaki ilişkinin "büyüklüğü" ve "anlamlılığı" arasındaki ilişkiyi temsil eden bir fonksiyona ihtiyacınız vardır. Bu fonksiyon size tam olarak "popülasyonda böyle bir ilişkinin olmadığı varsayılarak, belirli büyüklükteki bir örnekte belirli bir değerde (veya daha fazla) bir ilişki elde etmenin ne kadar muhtemel olduğunu" söyler. Başka bir deyişle, bu fonksiyon anlamlılık düzeyini (p-değeri) ve dolayısıyla belirli bir ilişkinin popülasyonda mevcut olmadığı varsayımının hatalı bir şekilde reddedilme olasılığını verecektir. Bu "alternatif" hipoteze (popülasyonda hiçbir ilişkinin bulunmadığına) genellikle sıfır hipotezi denir. Hata olasılığını hesaplayan fonksiyonun doğrusal olması ve farklı örneklem büyüklükleri için yalnızca farklı eğimlere sahip olması ideal olacaktır. Ne yazık ki bu işlev çok daha karmaşıktır ve her zaman tam olarak aynı değildir. Ancak çoğu durumda biçimi bilinir ve belirli bir büyüklükteki numunelerle yapılan çalışmalarda anlamlılık düzeylerini belirlemek için kullanılabilir. Bu fonksiyonların çoğu normal adı verilen çok önemli bir dağılım sınıfıyla ilişkilidir.
Bir regresyon modeli oluştururken, regresyon denkleminde (1) yer alan faktörlerin öneminin belirlenmesi sorusu ortaya çıkar. Bir faktörün öneminin belirlenmesi, faktörün yanıt fonksiyonu üzerindeki etkisinin gücü sorusunun açıklığa kavuşturulması anlamına gelir. Bir faktörün önemini kontrol etme problemini çözerken, faktörün önemsiz olduğu ortaya çıkarsa, o zaman denklemin dışında tutulabilir. Bu durumda faktörün yanıt fonksiyonu üzerinde anlamlı bir etkisinin olmadığı düşünülmektedir. Faktörün anlamlılığı doğrulanırsa regresyon modelinde bırakılır. Bu durumda faktörün yanıt fonksiyonu üzerinde ihmal edilemeyecek bir etkisinin olduğuna inanılmaktadır. Faktörlerin önemi sorusunu çözmek, bu faktörlere ilişkin regresyon katsayılarının sıfıra eşit olduğu hipotezini test etmeye eşdeğerdir. Böylece sıfır hipotezi şu şekilde olacaktır: boyut vektörünün alt vektörü (l*1). Regresyon denklemini matris formunda yeniden yazalım:
Y = Xb+e,(2)
e– n boyutunda vektör;
X- boyut matrisi (p*n);
B p büyüklüğünde bir vektördür.
Denklem (2) şu şekilde yeniden yazılabilir:
 ,
,
Nerede X kara X p - l - sırasıyla (n,l) ve (n,p-l) boyutunda matrisler. O halde H 0 hipotezi şu varsayıma eşdeğerdir:
 .
.
Fonksiyonun minimumunu belirleyelim  . Karşılık gelen H 0 ve H 1 = 1 - H 0 hipotezleri altında belirli bir doğrusal modelin tüm parametreleri tahmin edildiğinden, H 0 hipotezi altındaki minimum değer şuna eşittir:
. Karşılık gelen H 0 ve H 1 = 1 - H 0 hipotezleri altında belirli bir doğrusal modelin tüm parametreleri tahmin edildiğinden, H 0 hipotezi altındaki minimum değer şuna eşittir:
 ,
,
oysa H 1 için eşittir
 .
.
Sıfır hipotezini test etmek için istatistikleri hesaplıyoruz  (l,n-p) serbestlik derecesine sahip bir Fisher dağılımına sahip olup, H 0 için kritik bölge, F'nin en büyük değerlerinin yüzde 100*a'sından oluşur.
(l,n-p) serbestlik derecesine sahip bir Fisher dağılımına sahip olup, H 0 için kritik bölge, F'nin en büyük değerlerinin yüzde 100*a'sından oluşur.
Faktörlerin önemi birbirinden bağımsız olarak başka bir yöntem kullanılarak kontrol edilebilir. Bu yöntem, regresyon denkleminin katsayıları için güven aralıklarının incelenmesine dayanmaktadır. Katsayıların varyanslarını belirleyelim,  Değerler matrisin köşegen elemanlarıdır
Değerler matrisin köşegen elemanlarıdır  . Katsayı varyanslarının tahminleri belirlendikten sonra, regresyon denklemi katsayılarının tahminleri için güven aralıkları oluşturulabilir. Her tahmin için güven aralığı
. Katsayı varyanslarının tahminleri belirlendikten sonra, regresyon denklemi katsayılarının tahminleri için güven aralıkları oluşturulabilir. Her tahmin için güven aralığı  burada, öğenin belirlendiği serbestlik derecesi sayısı ve seçilen önem düzeyi için Öğrenci kriterinin tablo değeridir. Sayısı i olan bir faktör, bu faktörün katsayısının mutlak değeri, güven aralığını oluştururken hesaplanan sapmadan büyükse anlamlıdır. Başka bir deyişle i numaralı faktör, bu katsayı tahmini için oluşturulan güven aralığına 0 ait değilse anlamlıdır. Uygulamada, belirli bir anlamlılık düzeyinde güven aralığı ne kadar dar olursa, faktörün önemi konusunda o kadar emin olabiliriz. Öğrenci testini kullanarak bir faktörün önemini kontrol etmek için aşağıdaki formülü kullanabilirsiniz:
burada, öğenin belirlendiği serbestlik derecesi sayısı ve seçilen önem düzeyi için Öğrenci kriterinin tablo değeridir. Sayısı i olan bir faktör, bu faktörün katsayısının mutlak değeri, güven aralığını oluştururken hesaplanan sapmadan büyükse anlamlıdır. Başka bir deyişle i numaralı faktör, bu katsayı tahmini için oluşturulan güven aralığına 0 ait değilse anlamlıdır. Uygulamada, belirli bir anlamlılık düzeyinde güven aralığı ne kadar dar olursa, faktörün önemi konusunda o kadar emin olabiliriz. Öğrenci testini kullanarak bir faktörün önemini kontrol etmek için aşağıdaki formülü kullanabilirsiniz:  . Hesaplanan t-testi değeri, belirli bir anlamlılık düzeyinde ve karşılık gelen serbestlik derecesi sayısında tablo değeriyle karşılaştırılır. Faktörlerin önemini kontrol etmeye yönelik bu yöntem, yalnızca faktörlerin bağımsız olması durumunda kullanılabilir. Birbirine bağlı bir dizi faktörün dikkate alınması için bir neden varsa, bu yöntem, faktörleri yalnızca yanıt fonksiyonu üzerindeki etkilerinin derecesine göre sıralamak için kullanılabilir. Bu durumda anlamlılık testinin Fisher kriterine dayalı bir yöntemle desteklenmesi gerekir.
. Hesaplanan t-testi değeri, belirli bir anlamlılık düzeyinde ve karşılık gelen serbestlik derecesi sayısında tablo değeriyle karşılaştırılır. Faktörlerin önemini kontrol etmeye yönelik bu yöntem, yalnızca faktörlerin bağımsız olması durumunda kullanılabilir. Birbirine bağlı bir dizi faktörün dikkate alınması için bir neden varsa, bu yöntem, faktörleri yalnızca yanıt fonksiyonu üzerindeki etkilerinin derecesine göre sıralamak için kullanılabilir. Bu durumda anlamlılık testinin Fisher kriterine dayalı bir yöntemle desteklenmesi gerekir.
Böylece, faktörlerin yanıt fonksiyonu üzerinde önemsiz bir etkisi olması durumunda, faktörlerin öneminin kontrol edilmesi ve modelin boyutunun azaltılması sorunu ele alınmaktadır. Ayrıca burada, araştırmacıya göre deney sırasında dikkate alınmayan ek faktörlerin modele dahil edilmesi konusunu düşünmek mantıklı olacaktır, ancak bunların yanıt fonksiyonu üzerindeki etkisi önemlidir. Regresyon modeli seçildikten sonra şunu varsayalım:
 ,
,  ,
,
görev, modele ek x j faktörlerini dahil etme görevi ortaya çıktı, böylece bu faktörlerin tanıtıldığı model şu şekli alır:
 , (3)
, (3)
burada X, rütbe p'nin n*p boyutunda bir matristir, Z, g rütbesinin n*g boyutunda bir matristir ve Z matrisinin sütunları, X matrisinin sütunlarından doğrusal olarak bağımsızdır, yani. n*(p+g) büyüklüğündeki W matrisinin sıralaması (p+g)'dir. İfade (3) (X,Z)=W gösterimini kullanır,  . Yeni tanıtılan model katsayılarının tahminlerini belirlemek için iki olasılık vardır. Öncelikle tahmin ve dağılım matrisini doğrudan ilişkilerden bulabilirsiniz.
. Yeni tanıtılan model katsayılarının tahminlerini belirlemek için iki olasılık vardır. Öncelikle tahmin ve dağılım matrisini doğrudan ilişkilerden bulabilirsiniz.
İstatistikler uzun zamandır yaşamın ayrılmaz bir parçası haline geldi. İnsanlar her yerde bununla karşılaşıyor. İstatistiklere dayanarak, nerede ve hangi hastalıkların yaygın olduğu, belirli bir bölgede veya nüfusun belirli bir kesimi arasında neyin daha fazla talep edildiği hakkında sonuçlar çıkarılır. Hatta hükümet adaylarının siyasi programları bile buna dayanıyor. Bunlar ayrıca perakende zincirleri tarafından mal satın alırken de kullanılıyor ve üreticiler tekliflerinde bu verilere göre yönlendiriliyor.
İstatistikler toplum yaşamında önemli bir rol oynar ve her bireyi küçük şeylerde bile etkiler. Örneğin, belirli bir şehir veya bölgede çoğu insan giyimde koyu renkleri tercih ediyorsa, o zaman yerel perakende satış noktalarında çiçek desenli parlak sarı bir yağmurluk bulmak son derece zor olacaktır. Peki bu kadar etkisi olan bu veriler hangi niceliklerden oluşuyor? Örneğin, “istatistiksel anlamlılık” nedir? Bu tanımla tam olarak ne kastedilmektedir?
Bu nedir?
Bir bilim olarak istatistik, farklı nicelik ve kavramların birleşiminden oluşur. Bunlardan biri “istatistiksel anlamlılık” kavramıdır. Diğer göstergelerin ortaya çıkma olasılığının ihmal edilebilir olduğu değişkenlerin değerinin adıdır.
Örneğin, yağmurlu bir gecenin ardından sonbahar ormanında mantar toplamak için yapılan sabah yürüyüşünde 10 kişiden 9'u ayağına lastik ayakkabı giyiyor. Bir noktada 8 tanesinin kanvas mokasen giyiyor olma ihtimali ihmal edilebilir. Dolayısıyla bu özel örnekte 9 sayısı “istatistiksel anlamlılık” olarak adlandırılan değerdir.
Buna göre aşağıdaki pratik örneği geliştirirsek, ayakkabı mağazaları yaz sezonunun sonuna doğru yılın diğer zamanlarına göre daha fazla miktarda lastik çizme satın alıyor. Dolayısıyla istatistiksel bir değerin büyüklüğü günlük yaşamı etkilemektedir.
Elbette karmaşık hesaplamalarda, örneğin virüslerin yayılmasını tahmin ederken çok sayıda değişken dikkate alınır. Ancak istatistiksel verilerin önemli bir göstergesini belirlemenin özü, hesaplamaların karmaşıklığına ve sabit olmayan değerlerin sayısına bakılmaksızın benzerdir.
Nasıl hesaplanır?
Denklemin “istatistiksel anlamlılık” göstergesinin değeri hesaplanırken kullanılırlar. Yani bu durumda her şeye matematiğin karar verdiği söylenebilir. En basit hesaplama seçeneği, aşağıdaki parametreleri içeren bir matematiksel işlemler zinciridir:
- anketlerden veya nesnel verilerin incelenmesinden elde edilen iki tür sonuç, örneğin a ve b ile gösterilen satın alma miktarları;
- her iki grup için gösterge - n;
- birleştirilmiş numunenin payının değeri - p;
- “standart hata” kavramı - SE.
Bir sonraki adım genel test göstergesini belirlemektir - t, değeri 1,96 sayısıyla karşılaştırılır. 1,96, Öğrencinin t-dağılımı fonksiyonuna göre %95 aralığını temsil eden ortalama değerdir.

Genellikle n ve p değerleri arasındaki farkın ne olduğu sorusu ortaya çıkar. Bu nüans bir örnek yardımıyla kolayca açıklığa kavuşturulabilir. Diyelim ki kadın ve erkekler için bir ürüne veya markaya olan bağlılığın istatistiksel önemini hesaplıyoruz.
Bu durumda, harf tanımlarının ardından aşağıdakiler gelecektir:
- n - yanıt verenlerin sayısı;
- p - üründen memnun kalan kişi sayısı.
Bu durumda görüşülen kadın sayısı n1 olarak belirlenecektir. Buna göre n2 erkek var. P sembolü için “1” ve “2” sayıları aynı anlama gelecektir.
Test göstergesinin Öğrenci hesaplama tablolarındaki ortalama değerlerle karşılaştırılması “istatistiksel anlamlılık” olarak adlandırılan duruma gelir.
Doğrulama ne anlama geliyor?
Herhangi bir matematiksel hesaplamanın sonuçları her zaman kontrol edilebilir; çocuklara bu ilkokulda öğretilir. İstatistiksel göstergelerin bir hesaplama zinciri kullanılarak belirlendiğinden kontrol edildiğini varsaymak mantıklıdır.
Ancak istatistiksel anlamlılığın test edilmesi sadece matematikle ilgili değildir. İstatistik, her zaman hesaplanamayan çok sayıda değişken ve çeşitli olasılıklarla ilgilenir. Yani, makalenin başında verilen lastik ayakkabılarla ilgili örneğe dönersek, o zaman mağazalar için mal alıcılarının güveneceği istatistiksel verilerin mantıksal yapısı, kuru ve sıcak hava nedeniyle bozulabilir; bu, için tipik değildir. sonbahar. Bu durumun sonucunda lastik çizme satın alan kişi sayısı azalacak ve perakende satış mağazaları zarara uğrayacak. Elbette matematiksel bir formül, hava anormalliklerini tahmin edemez. Bu ana “hata” denir.

Hesaplanan önem düzeyini kontrol ederken tam olarak bu tür hataların olasılığı dikkate alınır. Hem hesaplanan göstergeleri hem de kabul edilen önem seviyelerini ve ayrıca geleneksel olarak hipotez olarak adlandırılan değerleri dikkate alır.
Önem düzeyi nedir?
“Seviye” kavramı istatistiksel anlamlılık için ana kriterler arasında yer almaktadır. Uygulamalı ve pratik istatistiklerde kullanılır. Bu, olası sapma veya hata olasılığını dikkate alan bir değer türüdür.
Seviye, hazır örneklerdeki farklılıkların belirlenmesine dayanır ve bunların önemini veya tersine rastgeleliğini belirlememize olanak tanır. Bu kavramın sadece dijital anlamları değil, aynı zamanda kendine özgü kod çözümlemeleri de var. Değerin nasıl anlaşılması gerektiğini açıklarlar ve sonucu ortalama endeksle karşılaştırarak seviyenin kendisi belirlenir, bu da farklılıkların güvenilirlik derecesini ortaya çıkarır.

Böylece seviye kavramını basitçe hayal edebiliriz - elde edilen istatistiksel verilerden çıkarılan sonuçlarda kabul edilebilir, olası bir hatanın veya hatanın bir göstergesidir.
Hangi önem seviyeleri kullanılıyor?
Uygulamada bir hatanın olasılık katsayılarının istatistiksel anlamlılığı üç temel düzeye dayanmaktadır.
İlk seviye, değerin %5 olduğu eşik olarak kabul edilir. Yani hata olasılığı %5 anlamlılık düzeyini aşmamaktadır. Bu, istatistiksel araştırma verilerine dayanarak yapılan kusursuz ve hatasız sonuçlara olan güvenin %95 olduğu anlamına gelir.
İkinci seviye %1 eşiğidir. Buna göre bu rakam, istatistiksel hesaplamalar sırasında elde edilen verilere %99 güvenle yön verilebilecek anlamına gelmektedir.
Üçüncü seviye %0,1’dir. Bu değerle hata olasılığı yüzde bire eşittir, yani hatalar pratik olarak ortadan kaldırılır.
İstatistikte hipotez nedir?
Kavram olarak hatalar, sıfır hipotezinin kabulü veya reddedilmesiyle ilgili olarak iki yöne ayrılır. Hipotez, tanımına göre arkasında bir dizi başka veri veya ifadenin yer aldığı bir kavramdır. Yani istatistiksel muhasebe konusuyla ilgili bir şeyin olasılıksal dağılımının açıklaması.

Basit hesaplamalarda iki hipotez vardır; sıfır ve alternatif. Aralarındaki fark, sıfır hipotezinin istatistiksel anlamlılığın belirlenmesinde yer alan örnekler arasında temel bir fark olmadığı fikrine dayanması ve alternatif hipotezin ise tamamen zıt olmasıdır. Yani alternatif hipotez, örneklem verileri arasında anlamlı bir farklılığın varlığına dayanmaktadır.
Hatalar nelerdir?
İstatistikte bir kavram olarak hatalar, doğrudan şu veya bu hipotezin doğru olarak kabul edilmesine bağlıdır. İki yöne veya türe ayrılabilirler:
- birinci tip, yanlış olduğu ortaya çıkan sıfır hipotezinin kabul edilmesinden kaynaklanmaktadır;
- ikincisi alternatifi takip etmekten kaynaklanmaktadır.

İlk hata türüne yanlış pozitif denir ve istatistiksel verilerin kullanıldığı tüm alanlarda oldukça sık görülür. Buna göre ikinci tip hataya yanlış negatif denir.
İstatistikte regresyon ne için kullanılır?
Regresyonun istatistiksel önemi, verilere dayanarak hesaplanan çeşitli bağımlılıklar modelinin gerçeğe ne kadar iyi karşılık geldiğini belirlemek için kullanılabilmesidir; dikkate alınması gereken faktörlerin yeterliliğini veya eksikliğini belirlemenize ve sonuç çıkarmanıza olanak tanır.
Regresyon değeri, sonuçların Fisher tablolarında listelenen verilerle karşılaştırılması yoluyla belirlenir. Veya varyans analizini kullanarak. Regresyon göstergeleri, çok sayıda değişkeni, rastgele verileri ve olası değişiklikleri içeren karmaşık istatistiksel çalışmalar ve hesaplamalar için önemlidir.
Etkinin önemi esasen karmaşık (integral) bir değerlendirmedir. Etkinin öneminin belirlenmesi birkaç aşamada gerçekleştirilir.
Aşama 1. Doğal çevrenin bireysel bileşenleri üzerindeki etkinin önemini belirlemek için etki kriterlerini içeren tabloların kullanılması gerekir (Tablo 5-1, 5-2 ve 5-3). Etki önem puanı formül 1 ile belirlenir.
Q ben = Q ben x Q ben x Q ben j
1 Kapsamlı bir etki değerlendirmesinde çarpma sırasında denklemi geçersiz kılan sıfır değerlerin varlığı nedeniyle sosyo-ekonomik metodolojide toplama sistemi kullanılmıştır.
doğal çevre
Q Ben
entegre - değerlendirilen etki için karmaşık değerlendirme puanı;
Qi t- geçici etki puanı i-th doğal çevrenin bileşeni;
Qi'ler- mekansal etki puanı i-th doğal çevrenin bileşeni;
Qi j- etki yoğunluğu puanı i-th doğal çevrenin bileşeni.
Önem kategorileri, doğal çevrenin farklı bileşenleri arasında tutarlıdır ve doğal çevrenin en büyük etkileri yaşayacak bileşenini belirlemek için halihazırda karşılaştırılabilir olabilir.
Bir ÇED yürütmek için üç etki önemi kategorisi benimsenmiştir: küçük, orta ve önemli, Metin Kutusu 5'te gösterildiği gibi.
Metin çerçevesi 5
| Etkilerin yaşanması ancak etkinin büyüklüğünün yeterince düşük olması (hafifletme olsun veya olmasın) ve kabul edilebilir standartlar dahilinde olması veya alıcıların duyarlılığının/değerinin düşük olması durumunda düşük önemde bir etki ortaya çıkar. |
| Orta derecede öneme sahip bir etki, etkinin düşük olduğu bir eşikten, yasal sınırı ihlal etmeye yakın bir seviyeye kadar geniş bir yelpazeye sahip olabilir. Mümkün olduğu takdirde, etkide orta derecede önemde bir azalma olduğuna dair kanıtlar gösterilmelidir. |
| Yüksek öneme sahip etkiler, kabul edilebilir sınırlar aşıldığında veya özellikle değerli/hassas kaynaklar üzerinde büyük büyüklükte etkiler gözlemlendiğinde ortaya çıkar. |
· toprak ve toprak altı üzerindeki etkiler;
· yüzey ve deniz suları üzerindeki etkiler;
· yeraltı suyuna etkisi;
· dip çökeltileri üzerindeki etki;
· hava kalitesi üzerindeki etki;
· deniz ve karadaki biyolojik kaynaklar üzerindeki etki;
· manzaralar üzerindeki etkiler;
· fiziksel etki faktörleri (gürültü etkileri, titreşim vb.).
Doğal çevrenin belirli bir bileşeni (atmosferik hava, yaban hayatı vb.) için belirlenen etkinin önemi tek ise, bu durumda doğrudan etkinin ortaya çıkan önemini değerlendirmek için kullanılır.
Uygulamada, doğal çevrenin bir bileşeni birden fazla kaynaktan gelen farklı etkilere maruz kalabilir, dolayısıyla doğal çevrenin belirli bir bileşeni için ortaya çıkan önem değerlendirmesi, etkinin önemini belirlemek için kullanılır. Elde edilen puanlara ve önem kriterlerine bağlı olarak ortaya çıkan etki önem değerlendirmesi belirlenebilir. Ortaya çıkan etki öneminin belirlenmesine ilişkin bir örnek Tablo 5-5'te sunulmaktadır.
7. Çevre denetimi – çevre yönetimi için ekonomik bir araç
Çevre denetimi çevre yönetimi için ekonomik bir araçtır.
Çevresel düzenlemenin ekonomik mekanizması, ticari kuruluşların kendi aralarında ve daha yüksek otoritelerle olan karmaşık, çok düzeyli bir ilişkiler sistemidir. Bu ilişkilerin bağlantı kolu, çevre korumanın organizasyonel ve ekonomik faktörlerini içeren bir araç olan çevre denetimi (EA) olmalıdır. Çevre koruma yapıları için en iyi seçeneği seçmenize, çevre koruma ekipmanının durumu ve çalışma derecesi hakkında bilgi ve analitik kontrol düzenlemenize ve planlanan teknik ve teknolojik gelişmelerin ekonomik bir değerlendirmesini yapmanıza olanak tanır.
Program geliştirme ve uygulama metodolojisinin hedeflerine, özelliklerine dayanarak, aşağıdaki tanımı öneriyoruz: EA, doğrudan veya dolaylı etkinin boyutunu belirlemek için herhangi bir mülkiyet biçimine sahip bir sanayi kuruluşunun ekonomik faaliyetinin tüm yönlerinin bağımsız bir çalışmasıdır. çevrenin durumu hakkında. Amacı, çevresel faaliyetleri mevzuat ve düzenlemelerin gerekliliklerine uygun hale getirmek, doğal kaynakların kullanımını optimize etmek, enerji tüketimini azaltmak ve kolaylaştırmak, atıkları azaltmak, acil durum deşarjlarını, emisyonları ve insan kaynaklı felaketleri önlemektir.
Bir işletmenin ekonomik faaliyetinin tüm yönlerinin incelenmesinden bahsettiğimiz için, EA, mevcut denetim türlerinin (üretim, finansal faaliyetler, uygunluk denetimleri) programlarını ve yöntemlerini birleştirmeli ve genişletmelidir.
Çevre denetçisinin raporu aşağıdaki bilgileri içerecektir:
o çevre ve üretim faaliyetlerinin mevzuat ve düzenlemelere uygunluğuna ilişkin sonuçlar;
o mali ve ekonomik raporlamanın durumu, muhasebe, zamanlılık ve mevcut çevresel ödemelerin miktarı, çevrenin korunması için tahsis edilen sermaye fonlarının kullanımının amacı hakkında sonuç;
o denetlenen işletmenin çevre durumu, üretim personelinin sağlığı, bölgedeki ekoloji üzerindeki etkisinin değerlendirilmesi, üretimi sınırlı veya yasak olan kirleticilerin emisyonlarının (deşarjlarının) varlığı ve büyüklüğüne ilişkin veriler devletin uluslararası yükümlülükleri gereği;
o ürün üretimindeki büyüme hızının ve kirleticilerin emisyon ve deşarj miktarlarının, enerji ve malzeme kaynaklarının tüketiminin analizinin sonuçları;
o denetlenen işletmenin ve Ukrayna ve diğer ülkelerdeki benzer işletmelerin çevre ve üretim faaliyetlerine ilişkin ana göstergelerin karşılaştırmalı analizinin sonuçları;
o acil bir durumda denetlenen işletmenin potansiyel tehlikesinin değerlendirilmesi, kazanın kaynağını ortadan kaldırmak için geliştirilen çalışma planının etkinliği, gerekli malzeme ve teknik araçların mevcudiyeti;
o işletmenin çevre hizmetleri çalışanlarının mesleki yeterliliği, bunların izin verilen kirlilik seviyelerine uygunluğun izlenmesi için modern teknik araçlarla sağlanması hakkında sonuç;
o Yönetim ve üretim personelinin, işletmelerinin neden olduğu çevre kirliliğinin miktarı ve niteliği, kirlilik düzeyinin azaltılmasına yönelik maddi ve manevi teşviklerin mevcudiyeti ve üretilen ürünlerin enerji ve malzeme yoğunluğu konusunda farkındalığı.
Çevre denetçisinin vardığı sonuca göre, belirli bir sorun (örneğin, belirli bir kirletici bileşenin miktarının veya konsantrasyonunun azaltılması) çeşitli, çoğunlukla alternatif yöntemlerle çözülebilir. Alınan kararın radikal niteliğine ve sorunun ciddiyetine bağlı olarak, gerekli çevre koruma önlemleri, organizasyonel önlemlerden teknolojik süreç üzerinde artan kontrole ve çevre koruma ekipmanının işletilmesinden işletmenin daha sonra başka bir amaca uygun olarak kapatılmasına kadar değişebilir. .
EA'nın dünyada gelişmesine katkıda bulunan önemli faktörlerden biri programın uygulanma prosedürüdür. Çevre denetimlerinin yapılması sürecinde sorumluların tespit edilmesi ve cezalandırılması asıl amaçtan uzaktır. Tesis faaliyetlerinin tüm alanlarında çevre üzerinde şu veya bu derecede olumsuz etkisi olan darboğazları tespit etmek ve bunların azaltılmasına yardımcı olmak şirket yönetimi için çok daha önemlidir. İşletmenin yönetim ve üretim personeli ile yakın işbirliği olmadan objektif bir çalışma yürütmek imkansızdır; kontrollü bir kişiden, görüşleri ve argümanları EA'nın tüm aşamalarında dikkate alınan tam bir ortağa dönüştürmeden.
EA, çevre sorunlarının yalnızca şirket yönetimini ilgilendirdiği ve bu yönetimin, üretim faaliyetlerinin olumsuz sonuçlarını, gizlenmesi imkansız hale gelecek ve bunların ortadan kaldırılmasının yasal gerekliliklere yol açacağı noktaya kadar, tehlikeleri kendilerine ait olmak üzere gizlemeye zorlandığı bir durum konusunda uyarıyor. işlemler ve yaptırımlar. Bu amaçla, belirli bir işletmenin çevre sorunlarının çözümüne bölgenin bilimsel potansiyelinin, çevre hizmetleri çalışanlarının ve finans kurumlarının dahil edilmesi tavsiye edilir.
Dünya Bankası'na göre, çevresel etki değerlendirmeleri ve ardından çevresel kısıtlamaların dikkate alınmasıyla bağlantılı proje maliyetlerindeki olası artış, ortalama 5-7 yıl içinde kendini amorti ediyor. Çevresel faktörlerin tasarım aşamasında karar verme sürecine dahil edilmesi, daha sonra ilave arıtma ekipmanı kurulumundan 3-4 kat daha ucuzdur ve ekolojik olmayan teknoloji ve ekipman kullanımının sonuçlarının ortadan kaldırılmasının maliyeti 30-35 kat daha fazladır. çevre dostu bir çözüm geliştirmek için gerekli olan maliyetlerden daha yüksek, temiz teknoloji ve çevre açısından gelişmiş ekipmanların kullanımı.
Çevre açısından denetlenen bir işletmenin çevrenin durumu üzerindeki kapsamlı etkisinin, ilgili tüm tarafların görüşleri dikkate alınarak objektif bir şekilde incelenmesi, çevresel ve ekonomik krizin daha da kötüleşmesini önlemeye ve çevresel ve ekonomik krizin daha da kötüleşmesini önlemeye yardımcı olacaktır. Ekonomik faaliyetin strateji ve taktiklerini geliştirirken çevresel faktör. Bu, işletmenin endüstriyel güvenliğini ve dolayısıyla yatırım çekiciliğini artıracaktır.
Gradyan yoluyla anlamlılık göstergelerinin belirlenmesi
Çift işlevli bir sinir ağı, değerlendirme fonksiyonunun eğimini giriş sinyallerinden ve ağın eğitilebilir parametrelerinden hesaplayabilir.
Bir q-o örneğini çözerken bir parametrenin öneminin göstergesi, w p parametresinin mevcut değeri seçilen değerle değiştirilirse, bir q-o örneğinin ağı tarafından çözüm değerlendirme fonksiyonunun değerinin ne kadar değişeceğini gösteren bir değer olacaktır. değer wp . Bu kesin değer, bir değiştirme yapılarak ve ağ tahmini hesaplanarak belirlenebilir. Ancak çok sayıda ağ parametresi göz önüne alındığında, tüm parametreler için anlamlılık göstergelerinin hesaplanması çok zaman alacaktır. Anlamlılık parametrelerini tahmin etme prosedürünü hızlandırmak için kesin değerler yerine çeşitli tahminler kullanılır. Anlamlılık göstergelerinin en basit ve en çok kullanılan doğrusal tahminini ele alalım. Değerlendirme fonksiyonunu birinci dereceden terimlere kadar Taylor serisine genişletelim:
burada H 0 q, w =w ile q-o örneğinin çözümü için değerlendirme fonksiyonunun değeridir. Böylece, bir q-o örneğini çözerken p-o parametresinin önem göstergesi aşağıdaki formülle belirlenir:
Anlamlılık göstergesi (1) çeşitli nesneler için hesaplanabilir. Çoğunlukla eğitilen ağ parametreleri için hesaplanır. Ancak (1) tipinin önem göstergesi sinyaller için de geçerlidir. Bu bölümde daha önce belirtildiği gibi, ters yönde çalışırken, ağ her zaman iki gradyan vektörünü hesaplar - eğitimli ağ parametrelerine ve tüm ağ sinyallerine dayalı değerlendirme fonksiyonunun gradyanı. Anlamlılık puanı en az anlamlı nöronu belirlemek için hesaplanıyorsa, nöron çıktısının anlamlılık puanı hesaplanmalıdır. Benzer şekilde, en az anlamlı giriş sinyalini belirleme görevinde, bu sinyalin uygulandığı bağlantıların ağırlıklarının önemlerinin toplamını değil, bu sinyalin önemini hesaplamak gerekir.
Eğitim seti üzerinden ortalama alma
X q p parametresinin anlamlılık göstergesi, parametre uzayında hesaplandığı noktaya ve eğitim setindeki örneğe bağlıdır. Örneğe bağlı olmayan bir parametrenin önemine ilişkin bir gösterge elde etmek için temelde iki farklı yaklaşım vardır. İlk yaklaşımda, eğitim setinin olası tüm örnekler hakkında eksiksiz bilgi içerdiği varsayılmaktadır. Bu durumda anlamlılık göstergesi, wp parametresinin mevcut değerinin seçilen wp değeri ile değiştirilmesi durumunda eğitim seti için değerlendirme fonksiyonu değerinin ne kadar değişeceğini gösteren bir değer olarak anlaşılmaktadır. Bu değer aşağıdaki formül kullanılarak hesaplanır:
Başka bir yaklaşımda eğitim seti, giriş parametreleri uzayında rastgele bir örnek olarak kabul edilir. Bu durumda, tüm eğitim seti üzerindeki anlamlılık göstergesi, eğitim seti üzerinden bazı ortalamaların sonucu olacaktır.
Birçok ortalama alma yöntemi vardır. Bunlardan ikisine bakalım. Ortalamanın bir sonucu olarak anlamlılık göstergesinin ortalama bir önem vermesi gerekiyorsa, böyle bir gösterge aşağıdaki formül kullanılarak hesaplanır:
Ortalamanın bir sonucu olarak anlamlılık göstergesinin, bireysel örnekler için anlamlılık göstergelerini aşmayan bir değer vermesi gerekiyorsa (bireysel bir örnek için bu parametrenin önemi O§ p'den fazla değildir), o zaman böyle bir gösterge hesaplanır. aşağıdaki formülü kullanarak:
Önemlilik göstergelerinin birikimi
Tüm önem göstergeleri, ağ parametre uzayında hesaplandıkları noktaya bağlıdır ve bir noktadan diğerine hareket ederken büyük ölçüde değişebilir. Bir degrade kullanılarak hesaplanan anlamlılık endeksleri için bu bağımlılık daha da güçlüdür, çünkü degradenin hesaplandığı parametre uzayındaki iki bitişik noktada en dik iniş yöntemi (bkz. bölüm ) kullanılarak eğitildiğinde, degradeler diktir. Uzayda bir noktaya bağımlılığı ortadan kaldırmak için birden fazla noktada hesaplanan anlamlılık göstergeleri kullanılır. Daha sonra (3) ve (4)'e benzer formüller kullanılarak ortalamaları alınır. Anlamlılık göstergelerinin hesaplanacağı parametre uzayındaki noktaların seçilmesi sorunu genellikle basit bir şekilde çözülür. Gradyan yöntemlerinden herhangi biri için çeşitli eğitim adımları boyunca, gradyan her hesaplandığında anlamlılık puanları da hesaplanır. Anlamlılık göstergelerinin toplandığı öğrenme adımlarının sayısı çok fazla olmamalıdır, çünkü çok sayıda öğrenme adımında, özellikle formül (4)'e göre ortalama kullanıldığında ilk hesaplanan anlamlılık göstergeleri anlamsız hale gelir.
Literatürün ve NeuroComp grubunun deneyiminin analizinden, zıt sinir ağları kullanılarak çözülebilecek aşağıdaki görevleri formüle edebiliriz.
1. Sinir ağı mimarisinin basitleştirilmesi.
2. Giriş sinyallerinin sayısının azaltılması.
3. Sinir ağının parametrelerini seçilen küçük bir değer kümesine düşürmek.
4. Giriş sinyallerinin doğruluğuna yönelik azaltılmış gereksinimler.
5. Verilerden açık bilgi elde etmek.
Bu bölümde tartışılan kontrast algoritmaları, gerekli minimum giriş sinyali setini seçmemize olanak tanır. Minimum sayıda giriş sinyali kullanmak, bir sinir bilgisayarının çalışmasını daha ekonomik bir şekilde düzenlemenize olanak tanır. Ancak minimal setin dezavantajları vardır. Küme minimum olduğundan, sinyallerden birinin taşıdığı bilgi genellikle diğer giriş sinyalleri tarafından desteklenmez. Bu, bir giriş sinyalinde hata olması durumunda ağın yüksek olasılıkla yanılmasına neden olur. Aşırı giriş sinyali setinde, her sinyalin bilgisi diğer sinyaller tarafından güçlendirildiğinden (çoğaltıldığından) bu genellikle gerçekleşmez.
Böylece bir çelişki ortaya çıkar - başlangıçta yedekli bir sinyal setinin kullanılması ekonomik değildir ve minimum bir sinyal setinin kullanılması, hata riskinin artmasına yol açar. Bu durumda, uzlaşmacı bir çözüm doğrudur - tüm bilgilerin kopyalandığı minimum bir set bulmak gerekir. Bu bölümde bu tür kümelerin güvenilirliği artırılmış şekilde oluşturulmasına yönelik yöntemler tartışılmaktadır. Ek olarak, ikinci türden kopyaların oluşturulması, hangi giriş sinyallerinin orijinal sinyal setinde kopyalara sahip olmadığını belirlemenize olanak tanır. Böyle bir "benzersiz" sinyalin minimum sete dahil edilmesi, bu sorunu çözmek için bir sinir ağı kullanıldığında, bu sinyalin değerinin doğruluğunu dikkatle izlemeniz gerektiğinin bir sinyalidir.
İki tür kontrastlama prosedürü vardır: parametrelerin önemine dayalı kontrastlama ve bozulmayan kontrastlama. Bu bölümde her iki kontrast prosedürü türü de açıklanmaktadır.
Bu bölümde parametrelerin ve sinyallerin önem göstergelerini belirlemek için bir yöntem açıklanmaktadır. Daha sonra parametrelerin öneminin belirlenmesinden bahsedeceğiz. Ağ sinyallerinin öneminin göstergeleri, parametrelerin sinyallerle değiştirildiği aynı formüller kullanılarak belirlenir.